Introduction
Data visualization has become an essential tool for businesses, organizations, and individuals to make sense of complex data and communicate their insights effectively. With the increasing volume and complexity of data, it’s crucial to choose the right data visualization platform that can help you get the most out of your data.
In this article, we’ll introduce 31 of the best data visualization platforms available in the market and provide a comprehensive overview of each platform’s key features, benefits, and drawbacks. We’ll also discuss the criteria for selecting the best data visualization platform and provide a comparison of the platforms based on these criteria.
- Ease of use: The platform should be user-friendly and intuitive, allowing users to create visualizations quickly and easily.
- Customization options: The platform should provide a range of customization options to meet the unique needs of different users and data sets.
- Integration with data sources: The platform should allow for seamless integration with various data sources, including databases, spreadsheets, and cloud-based platforms.
- Data privacy and security: The platform should ensure the privacy and security of data, particularly for organizations handling sensitive information.
- Scalability: The platform should be scalable to meet the growing needs of businesses and organizations.
- Affordability: The platform should be affordable, with a range of pricing options to meet the budget constraints of different users.
- User support and community: The platform should provide access to a strong user support community and a range of resources, including tutorials, forums, and documentation.
Tableau is a powerful data visualization platform that provides a range of tools and features for creating interactive, visually appealing, and insightful representations of data. Here are some of the uses of Tableau for data visualization:
- Dashboard creation: Tableau provides an intuitive drag-and-drop interface for creating interactive dashboards that can display multiple views of data in a single space. Users can customize the look and feel of their dashboards with a variety of themes, colors, and styles.
- Data exploration: Tableau’s visualization tools allow users to easily explore and discover insights in their data. The platform provides a range of tools for filtering, sorting, aggregating, and drilling down into data to uncover trends and patterns.
- Data storytelling: Tableau’s visualizations can be used to tell a story about the data, helping users to communicate insights and findings to stakeholders. The platform provides a range of options for customizing visualizations and adding annotations, making it easy to create visually appealing and impactful data stories.
- Data analysis: Tableau provides a range of tools for analyzing data, including descriptive statistics, forecasting, clustering, and regression analysis. These tools can be used to gain a deeper understanding of data and uncover hidden patterns and relationships.
- Data presentation: Tableau’s visualizations can be easily exported and shared, making it a great platform for presenting data to stakeholders. The platform provides options for publishing visualizations to the web, embedding them in presentations, or sharing them with others via Tableau Server or Tableau Public.
- Data integration: Tableau supports a wide range of data sources, including spreadsheets, databases, cloud-based platforms, and APIs. This makes it easy to integrate data from multiple sources and create a single, unified view of data.
- Scalability: Tableau is a highly scalable platform that can be used by organizations of all sizes. The platform is designed to handle large amounts of data and can be used to create visualizations and dashboards for a wide range of purposes, from simple data exploration to complex data analysis and modeling.
Power BI is a single, scalable platform for self-service , enterprise business intelligence data visualization tool that can connect to any data, visualise it, and easily integrate the visualizations into the apps you use every day. Here are some usage of Power BI for data visualization:
- Create distinctive reports: Power BI visualization is tailored with your KPIs and brand by simply connecting to, modelling, and visualising your data. Get quick, AI-powered responses to your business inquiries—even if you ask in casual language.
- Gain Insights: Power BI visualization will connect to all of your data sources with the scale necessary to analyse, promote, and share insights across your business while protecting data security, accuracy, and consistency to get the most out of your investments in big data.
- Make decisions: Power BI visualization will work together quickly on the same data, cooperate on reports, and exchange insights across well-known Microsoft Office programmes like Microsoft Teams and Excel. Give everyone in your organisation the tools they need to take timely, data-driven decisions that lead to strategic actions.
- End-to-end data protection: Power BI visualization improved data security for Power BI reports, dashboards, and datasets. Even when exported to other file types like Excel, PowerPoint, and PDF or shared outside of your organisation, persistent protection continues to function.
- Extensive data connectors: Power BI visualization with more than 500 free connectors available, you may get a complete picture for data-driven decision making. Access hundreds of on-premises and cloud data sources natively, including Dynamics 365, Azure SQL Database, Salesforce, Excel, and SharePoint.
QlikView is the best data visualization tool for transforming unstructured data into knowledge. It is widely used to compile, search, and visually analyse data so that it can be transformed into insightful business information. It is being used by businesses to quickly derive insights from data. With exceptionally user-friendly interfaces, it adds a whole new level of analytical insights to the data warehouses. In addition to locating connections between data and relationships, QlikView also does direct and indirect searches on all data. Here are key features of QlikView tool :
- QlikView Desktop :It is a visualization tool that provides an integrated development environment called QlikView Desktop that is used to build transformation models and extract data. This Windows-based platform lets you analyse data, make GUI layouts and visualizations, and export the results as reports.
- QlikView Server: QlikView provides the presentation layer between end users and servers made up of a combination of QlikView web servers and applications. With proper data access and security, QlikView documents, reports, delimited files, and dashboards are hosted, managed, and distributed using QlikView Server. The server has access points that enable it to connect with different data sources and receive real-time feedback, as well as an in-memory analytics engine.
- QlikView Publisher : Additionally, QlikView Publisher is a server-side programme that closely integrates with QlikView Script and gives users access to two key features:
- QlikView directly loads data from a variety of sources, including SAP Net, Informatica, SQL Server, standard files, etc. into QVW files.
- A tool for the QlikView visualization that is used to construct tasks and trigger-based reloads.
- QlikView Management Console(QMC): QlikView visualization tool has a management console that allows for centralised management of all the elements that make up the QlikView environment. It is used by administrators to deploy associative models on the server and to offer data access for a variety of documents.
- QlikView User Access: It is a front-end part of the QlikView visualization ecosystem and offers numerous entry points in the form of web browsers. These access points give users the ability to run database queries, get data from QlikView Server, and carry out other tasks using a laptop, desktop, or mobile device.
Oracle Business Intelligence (BI) is a data visualization technology and tools that offers the industry’s first integrated, end-to-end Enterprise Performance Management System. It includes BI foundation and tools – integrated array of query, reporting, analysis, alerting, mobile analytics, data integration and management, and desktop integration – as well as category-leading financial performance management applications, operational BI applications, and data warehousing. Here are some tools and features provide by Oracle BI visualization :
- Interactive Visualizations: With Oracle BI visualization users have access to a large variety of interactive dashboards, charts, graphs, and other data visualization tools. While prompts and suggestions from the system lead customers through the exploration process to unearth new insights, they can filter, drill down, or pivot data right from the dashboard.
- Oracle Exalytics: With Oracle BI visualization people may efficiently evaluate large datasets without the help of a technical expert like a data analyst.
- Self-Service: With the help of this analytical system, even non-technical people will be able to examine, arrange, and understand data. For employees with any degree of data literacy, the information is simple to grasp and share thanks to the clear visuals.
- Actionable Intelligence: With Oracle BI visualization, Users are better equipped to make judgements about company operations, quotas, forecasts, and much more by evaluating data and spotting trends.
- Proactive Alerts: Users can configure predefined alerts to deliver them real-time updates whenever the system is triggered or scheduled. Depending on the urgency of the warning, these notifications are transmitted via a preferred channel, such as email, internal file storage, or text messaging.
- Mobile Access: Oracle BI visualization helps the user’s on preferred mobile device, the entire solution is displayed with a unified interface. This covers gestural and multitouch interactions with advanced features like map graphics.
- Augmented Analytics: The application of machine learning and AI in the analytics process improves the user experience by streamlining every component of it. The Oracle BI visualization technology enables natural language search queries, remembers previous searches, and makes intelligent choices for the best visualization for each unique dataset.
- Spatial Visualizations: The Orace BI visualization tools are not restricted to two dimensions; the system also provides a map view in which the data is projected on a fully interactive map. A continuous color-fill feature, size-adjustable markers, image-marker customization options, numerous types of binning, and colour filling in any direction are all possible for this design.
SAP Lumira a visualization intelligence tool for building and visualising stories from datasets. It was previously known as a tool for visual intelligence, where users could construct tales to illustrate facts in graphical form and visualise data. Data is entered into Lumira as a data set, and documents can be built on Lumira by using filters, hierarchies, and computed columns. To properly visualise the data, you can choose from a variety of charts, including bar charts and pie charts. Here are some key features of SAP Lumira :
- SAP Lumira data visualization tool includes Chart Property Editor and other technical components .
- SAP Lumira visualization uses datasets to generate tales that are attractively visualised, allowing businesses to accept data and use it to generate insightful stories.
- Without requiring coding expertise, SAP Lumira visualiztion enables professionals to get data insights and aids enterprises in properly and quickly visualising data.
- SAP Lumira visualization tools are ideal for the businesses that want to share the visualization stories on different platforms as it helps the companies with the future market predictions.
- SAP Lumira visualization provides a wonderful mobile interface with responsive UI experience and has great interaction with SAP Cloud platform and Microsoft Office.
- When working with big data, SAP Lumira Visualization is gifted with the ability to produce graphical dashboards with charts and maps that are easy to understand and relate to. Consequently, it is perfect for data discovery and application integration.
TIBCO Spotfire Data visualization enables real-time analytics and visualization of current events, it enables streaming data in Spotfire® analytics. Spotfire Data Streams may mix live real-time data with historical data using native or simple to create custom data connectors thanks to its ultra-fast continuous query processing engine. Here are some of the features of this analytical technology :
- Immersive Visual Analytics: For visualization, data discovery, and point-and-click insights, the Spotfire analytics platform and the TIBCO Hyperconverged Analytics advantage provide a seamless, single-pane-of-glass experience. Engage interactively with historical and real-time data: Fully brush-linked, dynamic visuals allow you to drill down or across multi-layer, diverse data sources.
- Custom Analytics Apps: With the Spotfire Mods framework, you can quickly design and create scalable custom analytics and visualization apps that serve a specific purpose. Being a modder is simple thanks to our compact extension framework. Configure your app specifically to communicate more readily with any visualization library, API, or workflow—ALL within the Spotfire environment.
- Interactive AI: Spotfire analytic and visualization technology is more intelligent. In a matter of seconds, our recommendations engine identifies the most intriguing patterns in your data and provides direction for further exploration. You are empowered by bespoke expressions and data functions provided by Spotfire’s embedded data science capabilities. With native R and Python packaged engines, you can build and manage scripts in a single environment. You can also instantly access pre-trained, governed data science models.
- Real-time Decisions: TIBCO Spotfire Data visualization consumes and analyses both streaming and historical data as a part of the same analysis. Spotfire shortens the time between event and action to improve both human-in-the-loop monitoring and automated decisioning. This is accomplished by using streaming data sources to update analysis in real-time or by building cloud action processes directly from a visualization.
- Powerful GeoAnalytics: Spotfire geoanalytics’ enduring strength is well-known. Drill down within and between multi-layered map charts in a seamless, intuitive way for deeper insights and automatic context for location-based data. Recalculate models with automatic marking scheme modifications between visualization layers in real time.
- Intelligent Data Wrangling: Data preparation for analysis is sped up using Spotfire software. Data from many sources, especially big data sources, can be combined, cleaned, enhanced, and transformed all immediately inside the analysis environment. Edit inline with an automatically documented, editable, shareable lineage that satisfies audit requirements. Smart machine learning processes streamline data preparation by automating simple operations like AI-powered smart joins.
MicroStrategy is a Business Intelligence software which provides a variety of data analytics features. It provides Data Discovery, Advanced Analytics, Data Visualizations, Embedded BI, and Banded Reports and Statements as a suite of apps. To pull data for analysis, it may link to data warehouses, relational systems, flat files, web services, and a variety of other sources. MicroStrategy is a market leader in BI software because of features like beautifully styled reports, ad hoc query, thresholds and alerts, and automatic report dissemination. It is acknowledged by Gartner Magic Quadrant as a visionary. Here are some of the important features for data visualization :
- Data discovery: MicroStrategy visualization has the ability to connect and interact with any type of data source and gather and jumble data from several sources to generate useful reports. This software can gather data from several sources like flat files, relational sources, big data sources, cloud systems, etc.
- Data Wrangling: The capability of turning data into information that is useful and then modifying it to meet the user’s needs is referred to as “data wrangling.” MicroStrategy visualization uses a variety of data wrangling and parsing techniques to generate reports that are insightful and helpful. Both data scientists and business users can benefit from this feature.
- Data mining and predictive analysis : MicroStrategy visualization is a great tool for integrating data mining and data modelling tools from other companies. Many different types of users can make use of these tools to create and design reports that are accessible and predictive.
- Analytical functions : MicroStrategy Visualization provides a vast library of almost 300 functions, including OLAP, data mining, mathematical, financial, and other important tools for creating highly interactive and educational reports and performing statistical studies.
- Real-time dashboards and mobile platform : With MicroStrategy Visualization , you can create platforms that, once created, can be accessed and managed from any mobile device and offer real-time data monitoring.
- Embedded BI : The main benefit of utilising MicroStrategy is its ability to seamlessly interface with other programmes like IBM WebSphere, SharePoint, WebLogic, etc. that enable users to access pre-programmed development-ready portals.
Tableau Server data Visualization is an online platform that enables you to store and manage Tableau data sources, workbooks, reports, and dashboards made with Tableau Desktop. To make new workspaces, publish reports and dashboards, and share them with other users, you can use a web browser to access Tableau Server. It enables users to connect to a variety of data sources, including SQL servers, Excel files, text files, and more. Users can build links between various data variables by using data servers to combine data from both on-premise and on-cloud servers. Here are some core features of Tableau Server :
- Image Role : By using Tableau Server Visualization Image Role, you may increase insight comprehension and aid end users in connecting with and comprehending visualizations. A new field semantic called Picture Role provides a scalable and automated approach to import image assets into Tableau. Tableau can now encode images as exportable row or column headers by dynamically mapping them to links in your data. By using this new feature, it will be feasible to manage image assets externally and keep workbook sizes from growing to an unmanageable extent.
- Tableau Community : Utilise tools inspired by the Tableau Visualization Community to do common tasks more quickly. Replace specific data sources on a worksheet level without requiring laborious workarounds. By using the Rich Text Editor when creating on the web, text items can be hyperlinked to provide context and allow for additional research.
- Tableau Embedded Analytics : It Utilises Tableau Embedded Analytics to its full potential in a more scalable, flexible, and economical manner. Our most recent licence model allows for customizable pricing that works for your company by allowing you to pay for consumption rather than users. To optimise the return on your data efforts, our new option combines a cutting-edge licencing strategy with our top-notch analytics platform.
- Tableau External Actions: To assist in automating business operations and help you save time and money, Tableau External Actions offers a direct interaction with Salesforce Flow. You can conduct processes and make choices in context by connecting your dashboards to Salesforce without ever leaving Tableau. With just one click, you can now send a customer invoice, escalate a case, and do much more.
- Drive smarter decisions : Tableau visualization promotes confident decision-making and uses market-leading AI to maximise the value of your data. By incorporating Data Stories, automated plain-language tales, into dashboards, you can save time and make analytics simple for everyone. Using Ask Data, explore and respond to important business issues. Explore deeper with AI-driven insights by learning the “why” with Explain Data. To become a data-driven organisation, map your data journey with Tableau Blueprint.
- Deploy flexibility : Tableau visualization integrates deeply with your corporate architecture to make the most of your technological investments. Choose between on-premises and public clouds, setup servers, handle software updates, or grow hardware capacity in accordance with your needs. By discovering, sharing, collaborating, and studying data from your mobile device, tablet, or computer, you may connect to any data and amplify cooperation. With Tableau Advanced Management, which offers better scalability, increased efficiency, and enhanced security, you can build and expand mission-critical analytics while keeping control. To stay compliant more effectively, keep an eye on consumption in one environment.
SAP Crystal Reports is a BI application for creating analytical reports from SAP and other non-SAP data sources, including Microsoft Excel, Oracle, SQL Server, and MySQL. Knowing how to use this tool enables organisations to create sophisticated reports and make business choices that are correct and lucrative for them. Almost any data source can be used to generate reports using this system. Making sense of data and revealing significant relationships that could otherwise go undetected is made easier by the use of formulas, cross-tabs, sub-reports, and conditional formatting. Data analysis is made easier to grasp with the use of data visualization tools like maps and graphs that visually express information. Here are some advantages of SAP Crystal Reports Visualization :
- Flexible and customized report : Using SAP Crystal Reports, which has a high level design interface and effective procedures, you can easily produce properly structured, pixel-perfect reports.
- Powerful report delivery options : The end customers of the organisation can receive customised reports in the language and format of their choice.
- Data source connectivity : Direct access to information sources is possible. Data sources include native, ODBC, OLE DB, and JDBC access to relational, OLAP, web services, XML, enterprise data sources, and salesforce.com.
- Expanded support : By allowing more data to be exported to a single worksheet rather of spanning numerous worksheets, you can fully utilise the Excel file format.
- flexible report design : With drag-and-drop ease, easily create straightforward reports that offer sorting and grouping advice.
IBM offers an integrated business intelligence package called IBM Cognos Business Intelligence, which is web-based data visualization technology. It offers a toolkit for tracking events and data, doing analytics, and creating scorecards. The software comprises a number of elements created to satisfy the various information needs of a business. Like IBM Cognos Framework Manager, IBM Cognos Cube Designer, and IBM Cognos Transformer, IBM Cognos is made up of several parts. This business software offers a number of tools for data gathering and the creation of informative reports that are easy to understand. Cognos also provides the opportunity to view reports in XML format and export reports in either PDF or XML format. Here are some of the extensive features of this visualization technology:
- Connectivity : Spreadsheets and CSV files can be used to import data. Connect to a variety of data sources, such as SQL databases, Google BigQuery, Amazon, Redshift, and more, in the cloud or on-premises.
- Prepares Data : AI-assisted data preparation can help you clean your data more quickly. Data from various sources is cleaned and prepared, calculated fields are added, data is joined, and new tables are created.
- Create dynamic dashboards : IBM Cognos visulaization quickly designs interactive dashboards that are appealing. Drill down for additional information, share through email or Slack, and produce infographics automatically by dragging and dropping data.
- Identify patterns : Ask a query in straightforward English to the AI assistant to view a depiction of the response. To forecast seasonal trends, use time series modelling.
- Personalised reports : Autonomously keep your stakeholders informed. Create dynamic, customizable, multi-page reports that you can distribute in the forms that your stakeholders prefer.
- Get Insights : Without any prior knowledge of data science, gain deeper insights. With statistically reliable time-series forecasting, you may confirm what you already know, discover what you don’t, and detect patterns to take into account.
TIBCO Jaspersoft is an Embedded Analytics and Reporting Software. Jaspersoft embedded analytics software is the most flexible, customizable, and developer-friendly business intelligence platform in the world. Users can simply build their own reports using self-service environments created using Jaspersoft software. Create clear metadata labels for your data, then give users a drag-and-drop report builder to handle the rest. Here are some of the extensive features :
- Extensive Datasource Support : The TIBCO Jaspersoft database support as JasperReports Library is accessible via a variety of servers, including JDBC and JNDI connections, Java Bean DataSources, File CSV data sources, Custom JRDataSources, Hibernate Connections, Mondrian OLAP Connections, XMLA Server Connections, and Hadoop-Hive Connector.
- Flexible and Embeddable Server Architecture : TIBCO Jaspersoft is an open Standards architecture based on the Spring Framework. Additionally, it supports HTTP APIs, REST, and SOAP-based web services for easier application and workflow integration. It can also connect to current identity management systems and third-party external authentication and authorisation systems (LDAP, CAS, JAAS, etc.). alternatives for cloud (SaaS and PaaS), virtualized, and on-premises deployment and also capable of multi-touch applications and mobile applications.
- Centralized Reporting : It supports a variety of output formats, including HTML, XLS, XLSX, PDF, CSV, DOCX, RTF, Flash, ODT, ODS, etc. It offers self-service access to reporting and analytics.
- Data analytics : It contains drill-down, filtering, formatting, animation charting, and other interactive report-making features. Additionally, it allows dynamic queries based on end-user controls and selections.
- Optimised Dashboard : It is a web-based drag-and-drop dashboard designer that enables interactive tables, charts, cross-tabs, and analytic views for combining numerous reports into a single dashboard.
- Secured Data Access : It establishes user- and role-based access to resources, folders, reports, and dashboards. also the semantic/domain data layer’s row and column data security. Access and Usage Auditing is possible for compliance. Along with multi-tenancy, also handle tenants or organisations.
- OLAP Analysis : Multi-dimensional Expression Language (MDX) support for sophisticated analytical queries is provided by this software, which analyses data across multiple attributes and time periods. It has an integrated ad hoc analytical interface and a standard JPivot-based analytic interface that support drill down, drill across, drill up, pivot, filter, sort, and charts against OLAP and In-Memory data.
SAS Visual Analytics is an advanced, integrated platform for controlled discovery and exploration. Users can look at and comprehend patterns, trends, and linkages in data, even if they lack advanced analytical abilities. Reports and dashboards that track business performance can be easily created and shared. The quality of analytics is far higher than that of other BI. It has great visual data exploration features that enable speedy pattern recognition. Here are some extensive features :
- See the big picture : SAS Visualization make quick use of ideas and clearly defined related measurements to identify significant correlations in your data. Find, visualise, and narrate tales and insights that are simple to comprehend and to explain by combining machine learning with explanations in natural language. Investigate all possibilities, ascertain the cause of an event, and sift through your data to find opportunities that are buried deep. Highlight important links, outliers, clusters, and more automatically to illustrate crucial conclusions that motivate action.
- dynamic visuals : SAS Visualization customises beautiful interactive reports and dashboards. Key performance indicators should be succinctly summarised and shared online and via mobile devices. Executives and front-line employees may easily interact with and collaborate on insights, slice and dice them to find their own answers, and use them to better understand business performance.
- data insights : Without the need for programming, simple-to-use predictive analytics enables even business analysts to evaluate potential outcomes and make better, data-driven decisions. Manual experimentation is no longer necessary thanks to clever algorithms. Additionally, you can collaborate with specialists to concentrate on what is most important.
- geographical context : SAS Visualization merges traditional data with location data, you may give your analysis and visualizations a geographic context. In order to evaluate data in novel ways and find location-specific opportunities, location analysis brings the “where” factor to the foreground. This allows you to grasp the whole picture before making judgements.
- Streamline the discovery process : With drag-and-drop simplicity, self-service data preparation enables business users to import their own data, join tables, apply data quality functions, generate calculated columns, and more. SAS Visual Analytics helps your entire organisation adopt analytics more quickly and broadly by enabling users to access, integrate, clean, and prepare their own data in an agile and reliable manner.
- Chat-enabled insights : With the help of SAS Visualization, You can build and use unique, natural language chatbots using a simple, low-code visual interface. Through a conversational, natural language interface, you can access data, reports, and visualizations, receive text responses, and even use analytics and AI. Set up bots within the SAS environment for simpler insight access, or connect to third-party platforms to make them available globally. Insights from data can now be obtained as easily as sending a message.
- Open integration for developers : Enhance interactive creative visualization with third-party JavaScript libraries like D3 and C3 within SAS Visual Analytics. Access SAS analytics, data, and services by utilising open source development resources for programmers and REST APIs for any client language.
Power View makes it possible to interactively explore, visualise, and present data, which promotes natural ad-hoc reporting. Power View’s adaptable graphics make it possible to quickly study large data sets. The dynamic data visualizations make it simple to present the data with only one Power View report. Your workbook’s data model serves as the foundation for Power View. You can either begin with a Data Model that is already present in Power Pivot or you can build a Data Model directly from Power View. We will assume that you are familiar with Power Pivot’s Data Model fundamentals throughout this lesson. If not, we advise you to first read the Excel Power Pivot tutorial. Here are some features of Power View:
- Create Power View : Excel’s Power View add-in must be activated in order to create a Power View. Then, based on your Data Model, you can construct a Power View sheet with Power View, which can accommodate a variety of various data visualizations.
- Power View Sheet :The Power View sheet is made up of a number of different parts, including the Power View canvas, Filters area, Fields list, Layout regions, and Power View Ribbon tabs.
- Power View Visualizations : The main feature of Power View visualization is its numerous types of data visualizations, which let you portray the data, visualise it, and then explore it in a dynamic way. By quickly moving between different visualizations, diving up and down into the data, and exposing the substance of the data, you can handle big data sets with thousands of data points.
- Visualization with Multiples : Power View Visualization has the ability to display Chart representations in Multiples. In Power View, a grid of Charts with the same axis is possible. Vertical or horizontal multiples are both possible.
- Visualization with Tiles : It may take some time to scroll up and down when there is a lot of data to display at once. With Tiles, Power View Visualization makes this operation incredibly simple for you. Containers on a navigation strip depending on a field in your data are known as tiles. The value of the field is selected when you click on a Tile, and your visualization is filtered as a result. You can use data-bound graphics, such as sports images for Tiles, to provide your navigation strip with a visual indication.
- Hierarchies in Power View : You can construct a hierarchy to treat all of the nested fields in your data as one field if your data has nested fields. You can either use a hierarchy that is already established in the Data Model and that you created in Power View for visualization, or you can develop your own hierarchy in Power View and use it for visualization. In Matrix, Bar Chart, Column Chart, and Pie Chart visualizations, you can drill p and drill down the hierarchy. A Pie Chart with a Column Chart can have a hierarchical filter.
- Key Performance Indicator : Key performance indicators (KPIs) give you the ability to monitor your progress towards your stated objectives. From Power View, you may construct KPIs in the Data Model. The KPIs can then be depicted in attractive Power View visualizations, and aesthetically pleasing reports can be generated. Since it’s probable that the KPIs will need to be changed as time goes on, you can also edit the KPIs from Power View.
Users can create personalised dashboards and simple-to-read reports using Google Data Studio, a web-based application for data visualization. It aids in tracking important KPIs for clients, visualising trends, and evaluating performances over time. Google Data Studio (GDS) is a fantastic, free data visualization tool that enables you to create customizable, eye-catching reporting and interactive dashboards. Report sharing and scheduling are made simple by Data Studio’s many user-friendly features. We track important KPIs for clients using Data Studio, which also helps us to see trends and evaluate performance over time. The old Google Analytics interface, which has a remarkably small functionality range, is essentially upgraded in Data Studio. Here are some of the extensive features of GDS :
- Smart Dashboard : The UI and dashboard of Data Studio are similar to those of Google Drive. As a result, you have extensive knowledge of the tool’s user interface. You can look for reports, templates, and data sources using the top-left Search Data Studio box. You can change the visibility of Reports, Data sources, and Explorer under the Recent section.
- Data Collection Sources : By using Data Studio Visualization, you can avoid handling several copies of work-related Google Sheets or Microsoft Excel files. The programme can evaluate unprocessed data from more than 800 data sets and 490+ data connectors. As a result, you can now import data from third-party sources like Funnel, TapClicks, Amazon Seller Central, Asana, Jira Cloud, etc. Additionally, you can permit the tool to access and analyse data from other Google products, including Campaign Manager 360, Google Analytics, MySQL, and Google Sheets.
- BI Engine with Performance-Driven Memory : The BI Engine from the Google Cloud BigQuery team provides Data Studio with sub-second speed. It is a service for accessing and analysing data in memory that may be integrated with your personal BigQuery data warehouse. As a consequence, you may instantly update and load a dashboard with live data from hundreds of sources.
- Smart Data Visualization : The Data Studio report’s view mode responds quickly because of sophisticated programming capabilities like drill-downs, cross-chart interactions, and controls for chart interactivity. In order to gain different insights from your reports, a reader can change practically everything, from filters to metrics. By breaking down your graphs and tables into individual pieces of data, Data Studio Explorer allows the audience to go deep into your report. When viewing the databases in a report, viewers do not necessarily need to be specialists in SQL databases. The viewers have access to visual queries for database exploration.
- Real-Time Collaboration : You may collaborate on the same Data Studio report in real-time with your collaborators, much like with other Google productivity products. You can invite people to collaborate with you, control their access levels, or obtain a public link for social media from the Share menu at the top of the report. When you invite someone to join your Data Studio workspace, their Google profile will appear in the menu bar.
- Ease to Use : Users from Google Workspace are already accustomed to its user-friendly online interface. The workspace for altering reports allows for full drag-and-drop operations. For any item you utilise in your reports, you may access a panel with specific property options. If you utilise Data Studio’s ready-to-use templates, you also won’t need to spend a lot of time learning about graphs and tables. There are eight different report categories to pick from in the Templates collection.
- Setting Up a Report : Regularly sharing the data visualization report, or as the customer prefers, is a crucial duty. You can forget to provide project reports to your customer while you’re busy managing the team and different responsibilities. You may plan ahead with Data Studio’s Schedule email distribution tool. You may design a report for your customer and arrange for delivery. When the report is due, Data Studio will instantly let your customer know. You may also modify the Repeat settings to tell the tool whether the customer needs to view reports at specific intervals.
Plotly is an open-source Python data visualization package that supports a number of graph types, including line charts, scatter plots, bar charts, histograms, area plots, and others. In this post, we’ll look at how to use plotly to create a simple chart and how to make a plot interactive. But before getting started, you might be asking why learning plotly is necessary, so let’s have a look at that. Plotly creates interactive plots where we can zoom in on the graph or add more information like data on hover and many other things using Javascript in the background. Here are some of the extensive features :
- Easy to Use : Plotly Visualization is an easy-to-use data visualization programme that provides quite sophisticated visualization features. To effectively utilise all tools and capabilities, no special expertise or knowledge is required. Even more, it offers an open development methodology that enables users to completely customise functionality. The dashboard’s simplicity and cleanliness make it less intimidating for beginners.
- Modern Analytics : Plotly visualization is brimming with powerful analytics capabilities that can handle computations for NLP, ML, forecasting, and more. Working with the well-known Python, Julia, and R languages is free for data scientists.
- Greater Productivity : Through the use of centralised project dashboards, users may quickly speed up work and prevent bottlenecks and delays. Teams may easily communicate and share files.
- Reduced Costs : Plotly visualization is capable enough for consumers to do without the requirement for a specialised group of IT specialists and developers. It can perform duties that call for an IT staff, front-end developers, and back-end developers. Additionally, it provides a wide range of pricing options that can meet users’ demands for both on-premises and cloud-based solutions.
- Scalability : Plotly visualization can assist lone researchers, SMBS, startups, and even large organisations. Even for lone practitioners and small teams, all enterprise-grade technologies are accessible.
- Total Customization : Any user’s experience with Plotly can be completely customised using its open API. It can simply operate with pre-existing workflow architecture and interface with third-party programmes.
A JavaScript package called D3.js allows users to manipulate documents using data. Using HTML, SVG, and CSS, D3 enables you to bring data to life. With its focus on web standards, D3 combines strong visualization components with a data-driven approach to DOM manipulation, giving you access to all the features of contemporary browsers without shackling you to a proprietary framework. It is becoming more challenging to communicate this information due to the enormous volume of data being generated today. The most efficient way to communicate important information is through visual representations of data, and D3 makes it very simple and flexible to generate these types of data visualizations. It is dynamic, intuitive, and requires the least amount of work. Here are some of the features of D3.js technology:
- Uses Web Standards: To build interactive data visualizations, D3 is a very potent visualization tool. It uses SVG, HTML, and CSS, three current web standards, to produce data visualization.
- Data Driven: D3 is data-driven. To construct various sorts of charts, the programme can use static data or obtain information from a remote server in a variety of forms, including Arrays, Objects, CSV, JSON, XML, etc.
- DOM Manipulation: Based on your data, D3 lets you modify the Document Object Model (DOM).
- Data Driven Elements: Whether it’s a table, a graph, or any other HTML element and/or set of elements, it gives your data the ability to dynamically construct elements and apply styles to the elements.
- Dynamic Properties: Most of its functions may be provided with dynamic properties thanks to D3. Data functions can be used to specify properties. This implies that your styles and characteristics can be driven by your data.
- Types of visualization: There are no established visualization formats for D3. However, it allows you to construct anything, including geographical maps, graphs, and bar charts, as well as an HTML table and a pie chart.
- Custom Visualizations: D3 allows you maximum control over your visualization features because it complies with web standards.
- Transitions: The transition() function is offered by D3. Because D3 inherently develops the logic to extrapolate between your numbers and identify the intermittent phases, this is incredibly potent.
- Interaction and animation: D3 has excellent animation support with features like duration(), delay(), and ease (). Animations that transition quickly between states and are responsive to user input.
Highcharts is a charting library built entirely on JavaScript that is intended to improve online applications by enabling interactive charting. There are several different charts available on Highcharts. Examples include bar charts, pie charts, line charts, spline charts, area charts, and so forth. A charting software package called Highcharts was first made available in 2009. It is entirely written in JavaScript. It was developed by Highsoft in Vik, Norway, and has frequently been discussed in publications like Finansavisen and Dagsrevyen.
- Compatability : Highcharts visualization works flawlessly on all popular browsers and mobile operating systems like iOS and Android.
- Multitouch Support : Highcharts visualization supports multitouch on systems with touch screens, such as iOS and Android.
- Free to Use : Ideal for Android and iPhone/iPad-based smart phones and tablets.
- Lightweight : highcharts.js core library with size nearly 35KB, is an extremely lightweight library.
- Simple Configurations : Highcharts visualization uses json to define various configurations of the charts and is very easy to learn and use..
- Multiple axes : Highcharts visualization is not limited to the x and y axes. It allows for numerous chart axes.
- Configurable tooltips : When a user hovers their cursor over a chart point, a tooltip appears. Highcharts has a tooltip intrinsic formatter or callback formatter to allow programmatic control of the tooltip.
- DateTime support : Highcharts visualization specifically handles date and time. offers a wide range of built-in controls for date-based categories.
- Export : Chart can be exported in PDF, PNG, JPG, or SVG format by turning on the export feature.
- External data : Highcharts visualization supports dynamic data loading from a server. gives users access to data control using callback functions.
FusionCharts is a charting and data visualization tool built on JavaScript that pulls raw data from countless sources and turns it into insightful information. It offers a wide variety of live templates to develop mobile or web dashboards, including 2000 different map styles and more than 150 chart types. Mobile and web developers can use it because it connects with JavaScript frameworks and server-side programming languages. Here are some additional features :
- Powerful Visualization : Using FusionCharts collection of sturdy components, you may transform enormous amounts of data into insightful reports and show them on an interactive dashboard.
- Compatible Installation : Using SWF file copy and paste, make visually appealing charts. supports and functions with servers that forbid the installation of any kind of components.
- Hassle-Free : Animated and interactive charts can be made using XML, URLs, or JSON as the data interface. Increase the productivity of the process for designers and developers by converting data into XML using the visual GUI.
- Ease of Use : Initially, there is no learning curve. Using FusionCharts visualization provides easily accessible instructions, creating visualization charts in 15 minutes.
- Transparent Licensing Policies : neither production nor testing servers are subject to a per-server fee. Once you’ve bought the licence, you can use accessible hosting across several servers.
- Free Trial : Before completing the final payment, 14 days of the free version can be used.
- Flexible Pricing :FusionCharts visualization provides a variety of adjustable pricing options based on consumption, such as internal vs. SaaS, team size, and upfront vs. annual.
The leaflet is an open-source library that makes it simple to visualise spatial data. The reason it has become the most widely used map library in the world is because it is an open-source library that can be included into any platform and computer language. A framework for displaying map data is called Leaflet. The developers are required to give the data and base map layer. The maps include browser compatibility, built-in interactivity, panning and zooming, and are made up of tile layers. Here are some of the extensive features of Leaflet :
- Layers Out of the Box : Leaflet.js supports various layers including Tile layers, WMS Markers, Popups.It also involves Vector layers such as polylines, polygons, circles, rectangles, Image overlays and GeoJSON.
- Customization : Leaflet.js contains Pure CSS3 popups and controls for easy restyling Image- and HTML-based markers. A simple interface for custom map layers and controls. This supports a custom map projections and powerful OOP facilities for extending existing classes.
- Map Controls : Leaflet.js supports map visualization which supports features such as Zoom buttons, Attribution, Layer switcher and Scaling.
- Interaction Features : Leaflet.js contains various interactive features for ease of use contains Drag panning with inertia, Scroll wheel zoom, Pinch-zoom on mobile, Double click zoom, Zoom to area (shift-drag), Keyboard navigation and external mouse controls such as Events: click, mouseover and Marker dragging
- Visual Features : There are a number of aesthetic features, like Tile and popup fade animation, Zoom and pan animation, and more. Additionally, Retina resolution support and a Very Nice Default Design for Markers, Popups, and Map Controls
- Browser Support : It supports several Browses which includes Desktop, Chrome, Firefox, Safari 5+, Opera 12+, IE 9–11 and Edge. Also Mobile browser such as Safari for iOS 7+, Chrome for mobile, Firefox for mobile, IE10+ for Win8 devices.
Datawrapper is an intuitive web visualization application that enables you to upload data to produce graphs, charts, and maps. It can be used to make charts and graphs without any prior coding experience, making it ideal for journalists and data scientists searching for basic data visualization. Both PCs and mobile devices can use datawrapper. It offers a wide range of the greatest data visualization techniques, giving you greater freedom and enhancing the value of your reports. Datawrapper can generate interactive graphs and charts for you in a matter of minutes once you input datasets as CSV files and upload them. After that, you can save it as a JPG file or embed code. Some features of Datawrapper :
- Visualization : Web maps, charts, and tables are just a few of the three ways that Datawrapper helps organise data, making it perfect for integrating images into websites. The charts and maps in Datawrapper stand out because of how responsive and interactive they are.
- Reports Analysis : Your content management system (CMS) can be combined with Datawrapper to provide online visualizations for web and PDF reports. With the use of this technology, data scientists can also incorporate interactive PowerPoint designs that include charts.
- Deployment : Although Datawrapper is primarily hosted in the cloud, you can install it as a web-based tool or as SaaS (software-as-service). Although it can be used on several devices, Datawrapper deployment is device-specific.
- Customer Support : Customers who might need assistance using the tool or have queries can contact Datawrapper via email. However, there isn’t a designated phone number for those who might like to contact a representative.
- Ease of Use : It’s really simple to utilise Datawrapper. Without knowing any code or graphic design, it offers a straightforward interface for making charts and graphs. Additionally, you can use Datawrapper without creating an account. It enables you to import CSV or PDF files.
- Navigation : On its website, Datawrapper offers tutorials to show beginners how to use the programme. Slides, modules, and activities are included in this training to gauge how well you comprehend the technology. If you have any inquiries concerning the training materials, you can also get in touch with support.
RAWGraphs is an open source data visualization framework created with the intention of making it simple for anyone to visualise complex data. RAWGraphs, a tool primarily designed for designers and visualization enthusiasts, tries to bridge the gap between spreadsheet programmes like Microsoft Excel, Apple Numbers, and OpenRefine and vector graphics editors like Adobe Illustrator, Inkscape, and Sketch. DensityDesign Lab, along with Calibro, has been maintaining the project from its inception in 2013. Both delimiter-separated values (found in csv and tsv files) and copied and pasted text from other programmes can be used with RAWGraphs. Visualizations based on the svg format can be quickly altered with vector graphics programmes for additional refinement or immediately incorporated into web pages.
Some features of RawGraphs Visualization are :
- Open and free : As designers and/or developers working with data visualization, we must admit that without the existence of various free and open source solutions, our job would undoubtedly be very different. We consider a number of already-existing projects, such as Gephi, Open Refine, D3js, or Scriptographer, which we were able to utilise for free and which influenced our work methods and technical expertise. We wanted to give something back by enabling individuals to experiment with visualization and improve their data literacy for nothing.
- Privacy Maintained : Although RAWGraphs Visualization is a web application, only the web browser will process the data you enter. Nobody will see, touch, or copy your data because no server-side actions or storages are used.
- Optimized output : Your visualizations can be exported from RAWGraphs as.svg files. To alter them as you see fit, open them in your preferred vector graphics programme. No longer are PDFs or raster pictures hard to modify.
CARTO is a cloud computing platform known for offering GIS, online mapping, and spatial data research capabilities. The company’s technologies, which can analyse data and visualise it without prior GIS or development knowledge, are what distinguish it as a location intelligence platform. Users of CARTO have the option of using the company’s free platform or setting up their own instance of the open source programme. Using PostGIS and PostgreSQL as its foundation, CARTO is open source software. The tool heavily relies on JavaScript for its front-end web applications, back-end Node.js-based APIs, and client libraries. The platform of CARTO is made up of a number of essential parts. Here are some of the features of Carto :
- CartoFrames : This Python packages may be updated interactively and in real time, much like dynamic notebooks. It enables you to incorporate information from your CARTO account, such as maps and statistics, into your existing setting.
- Machine Learning : CARTO specialises at tasks that need extensive data analysis. By utilising SQL call statements, machine learning may be integrated into CARTO. You may use machine learning models to translate huge data into measurable answers by combining CARTO with Databricks.
- Geoenrichment : Geoenrichment is the process of leveraging location to improve the feature qualities. You may, for instance, geoenrich your data streams depending on demographics, financial data, and sites of interest.
- CARTO Builder : For programmer and non-programmers both, CARTO Builder offers a drag-and-drop online map. You may use spatial analytic tools to generate dashboards that you can share in a matter of minutes.
- Solution Tools : The CARTO platform might be useful if you want a collection of tools that carry out a certain task. To aid with commercial difficulties, tools including site selection, territory planning, and truck routing are available.
An powerful and adaptable map service called Mapbox Visualization may be included in mobile applications. The Mapbox tilesets provide developers access to detailed geographic data so they may design and alter dynamic and static maps. With the help of the given JavaScript library or the corresponding iOS and Android SDKs, the stylized maps may be added to online applications or mobile apps. For websites and applications like Foursquare, Lonely Planet, the Financial Times, The Weather Channel, Instacart Inc., and Snapchat, Mapbox, an American company, offers personalised online maps. Some open source mapping tools and libraries, such as the Mapbox GL-JS JavaScript library, the TileMill cartography IDE, the Leaflet JavaScript library, and the CartoCSS map styling language and parser, were developed by or were influenced by Mapbox. Here are some of the extensive features :
- Interactive maps :Mapbox Visualization create beautiful maps to show data in novel ways that assist people in finding insights. Smooth vector basemaps with visuals like those in video games and scaling to millions of data points. With Mapbox Studio, you can extrude and animate maps and data layers by altering colour ramps, zooming, and more. You can also customise your map design or choose from professionally created designs.
- Analytics : Mapbox Visualization analyze your data dynamically in-app and visualise it using heatmaps, isochrones, clusters, choropleths, 3D maps, and more. With Mapbox GL, drill down to gradually reveal data layers, such as global borders, zip codes, and locations of interest.
- Cross-platform support : Launch Mapbox Visualization anywhere. With the Maps SDK for iOS and Android, you can create mobile applications that are completely native and interactive much like those on the web. Install Atlas Server behind your own cloud architecture to deploy your full solution on-premise. Create completely functioning offline maps in any style without requiring a connection to the internet.
- Global data : Mapbox Visualization utilises the world-wide street and address-level data architecture of Mapbox to display user data while keeping it in your possession rather than ours. Use the Geocoding API to visualise statistics for each Swiss canton, Chinese prefecture, or French arrondissement. Use Mapbox boundaries to visualise international postal and administrative borders for choropleths and data merges.
Google Charts is a charting library built entirely on JavaScript that is intended to improve online applications by enabling interactive charting. It accommodates a variety of charts. In common browsers like Chrome, Firefox, Safari, and Internet Explorer, charts are created using SVG (IE). The visuals in IE 6 are drawn using VML. Here are some features of Google chart visualization :
- Compatibility :Google Charts Visualization works flawlessly on all popular browsers and mobile operating systems including iOS and Android.
- Multitouch Support : Google Charts Visualization supports multitouch on systems with touch screens, such as iOS and Android. Ideal for Android- and iPhone/iPad-based smartphones and tablets.
- Free to Use : Google Charts Visualization is free to use for non-commercial purposes and open source.
- Lightweight : The basic library for loader.js is quite compact.
- Simple Configurations : Google Charts Visualization uses json to create different chart configurations, and it’s really simple to understand and use.
- Multiple axes :
- Configurable tooltips : When a user hovers their cursor over a chart point, a tooltip appears. GoogleCharts offers a tooltip inherent formatter or callback formatter to programmatically manipulate the tooltip.
- DateTime support :Google Charts Visualization specifically handles date and time. offers a wide range of built-in controls for date-based categories.
Flot is a pure JavaScript plotting library for jQuery, with a focus on simple usage, attractive looks and interactive features.
DataPandit is a cloud analytics solution for seasoned chemometrician, statisticians, machine learning engineers, and material scientists. It offers no coding machine learning solutions to build powerful predictive models and data visualizations. Here are some of the uses of DataPandit for data visualization:
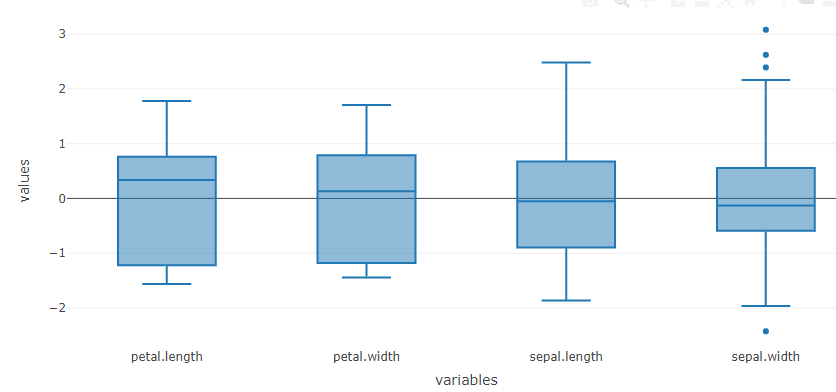
- Box-plot: It shows the median, quartiles, and outliers of a dataset, providing a useful summary of the data’s central tendency and variability.
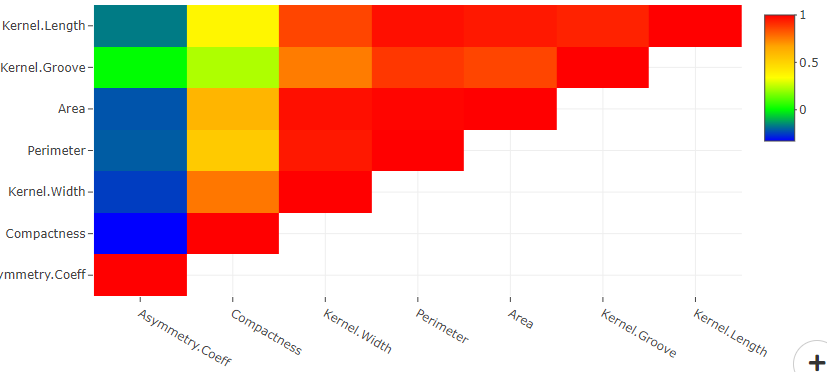
- Correlation Matrix: It shows the strength and direction of relationships between multiple variables. It is a table that displays the correlation coefficients between each pair of variables in the form of a matrix. The coefficients range from -1 (perfect negative correlation) to 1 (perfect positive correlation), providing a visual representation of the strength of relationships. Users can visualize strength of relationships and multicollinearity within variables using correlation matrix.
- Spectra Plots: distributed across a range of frequencies or wavelengths, allowing for the identification of peaks, troughs, and patterns in the material characterization data. They can be used to analyze and compare the spectra of different signals or substances, providing insights into their composition and behaviour.
- PLS Plots: A PLS (Partial Least Squares) plot is a type of data visualization used in chemometrics and analytical chemistry. It is used to visualize the relationship between two sets of variables in a dataset, typically with the goal of reducing the dimensionality of the data while retaining as much information as possible. The PLS plot displays the variables in a reduced, two-dimensional space, allowing for the visual comparison and analysis of the relationships between variables. The plot is particularly useful for exploring complex, multivariate datasets and identifying patterns and relationships within the data.
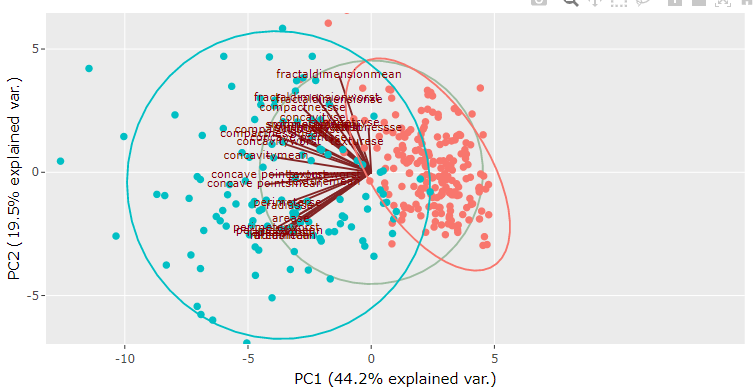
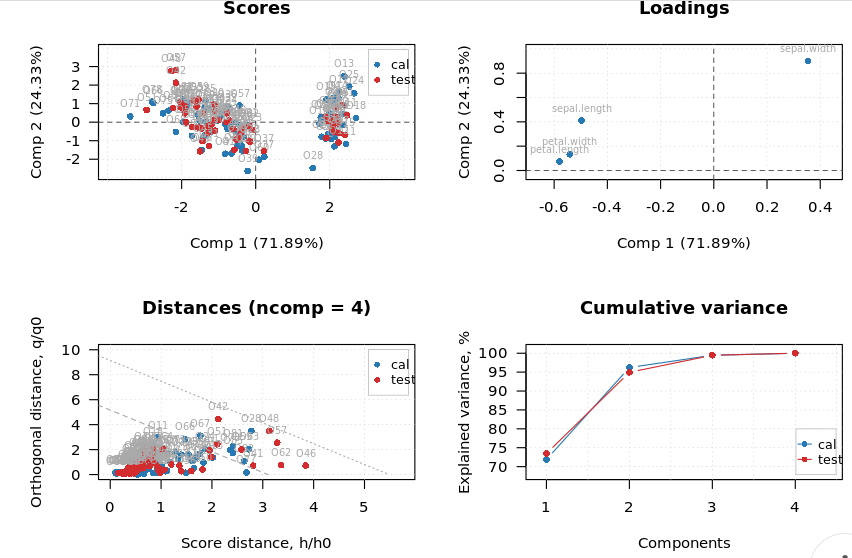
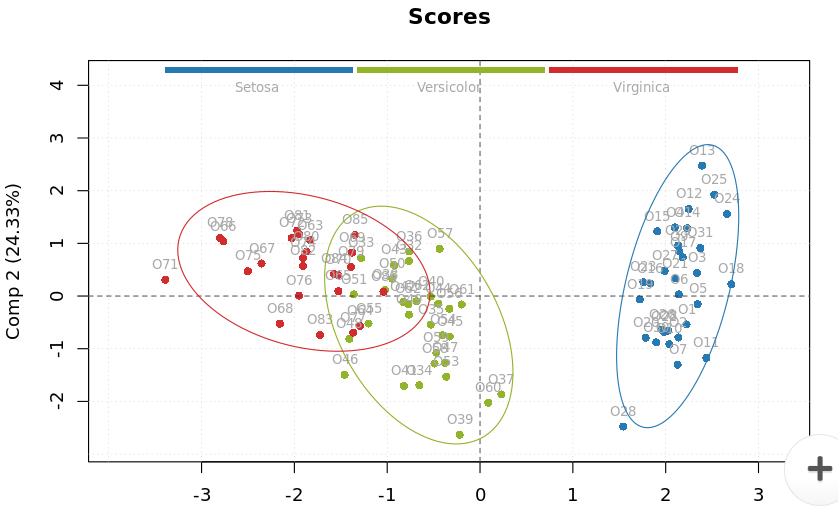
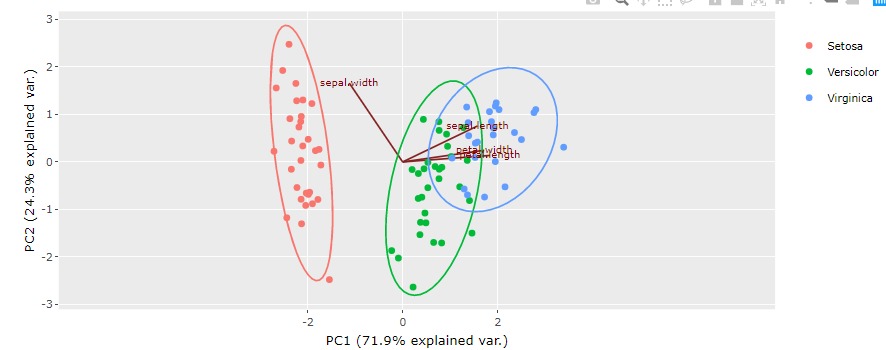
- PCA Plots: A PCA (Principal Component Analysis) plot is a type of data visualization that represents high-dimensional data in a lower-dimensional space. It is commonly used in fields such as statistics, machine learning, and data science to visualize complex, multi-dimensional data. The PCA plot displays the data points in a two-dimensional space, representing the most important relationships between variables. The plot allows for the identification of patterns, trends, and clusters within the data, providing insights into the underlying structure of the data. It can also be used to reduce the complexity of large, high-dimensional datasets, making it easier to visualize and understand the relationships within the data.
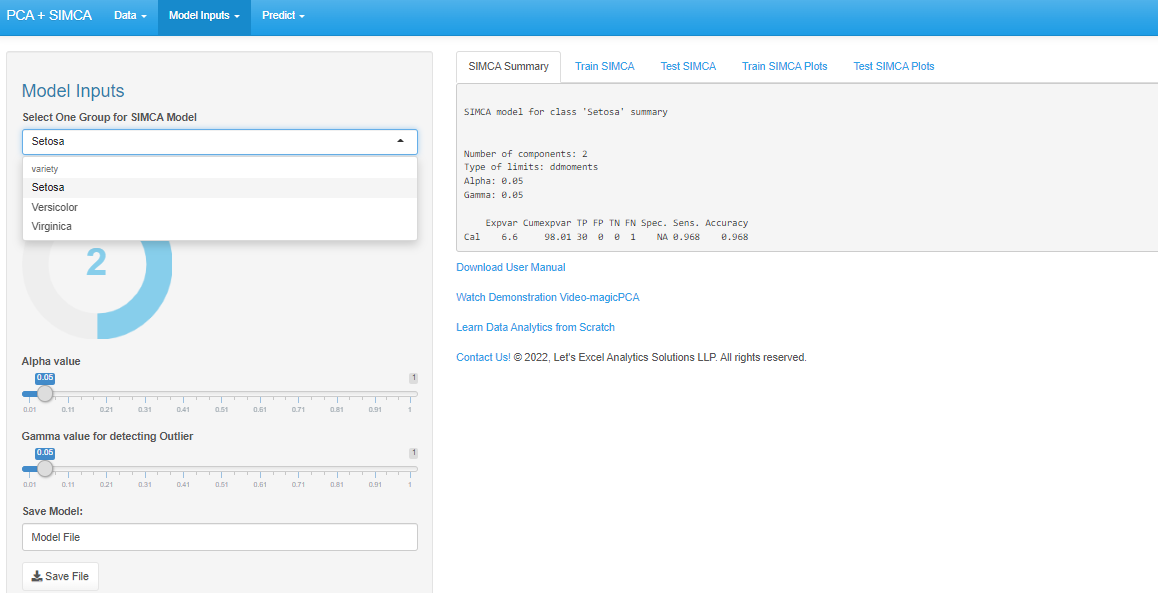
- SIMCA Plots: A SIMCA (Soft Independent Modeling of Class Analogies) plot is a type of data visualization used in chemometrics and analytical chemistry. It is used to classify and visualize large, complex datasets by modelling the relationships between variables. The SIMCA plot displays the grouping patterns in data points in a two-dimensional space. The SIMCA plot can also be used to classify new data points based on their relationships with the modelled data.
- LDA Plots: A LDA (Linear Discriminant Analysis) plot is a type of data visualization used in machine learning and data science to visualize the relationships between variables and class labels in a dataset. The plot represents the data in a lower-dimensional space, allowing for the visual comparison and analysis of the relationships between variables. The LDA plot is used to identify the most important variables for differentiating between class labels, and to visualize the relationships between variables and class labels in a clear and interpretable way. The plot can be useful for exploring the structure of a dataset, identifying patterns and trends, and improving the accuracy of classification models.
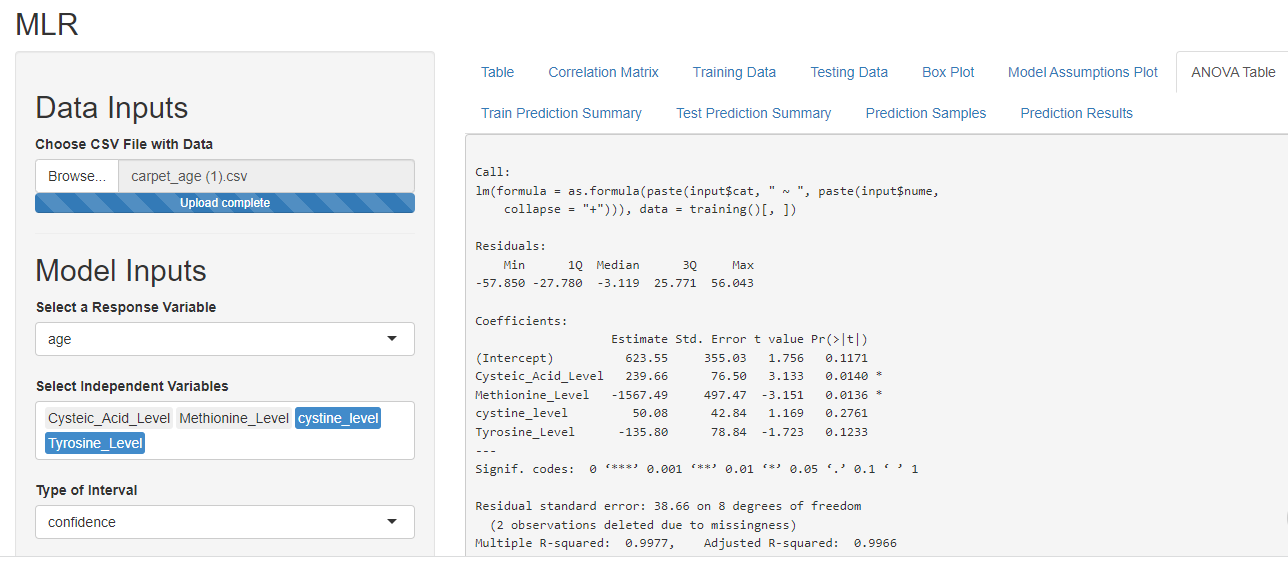
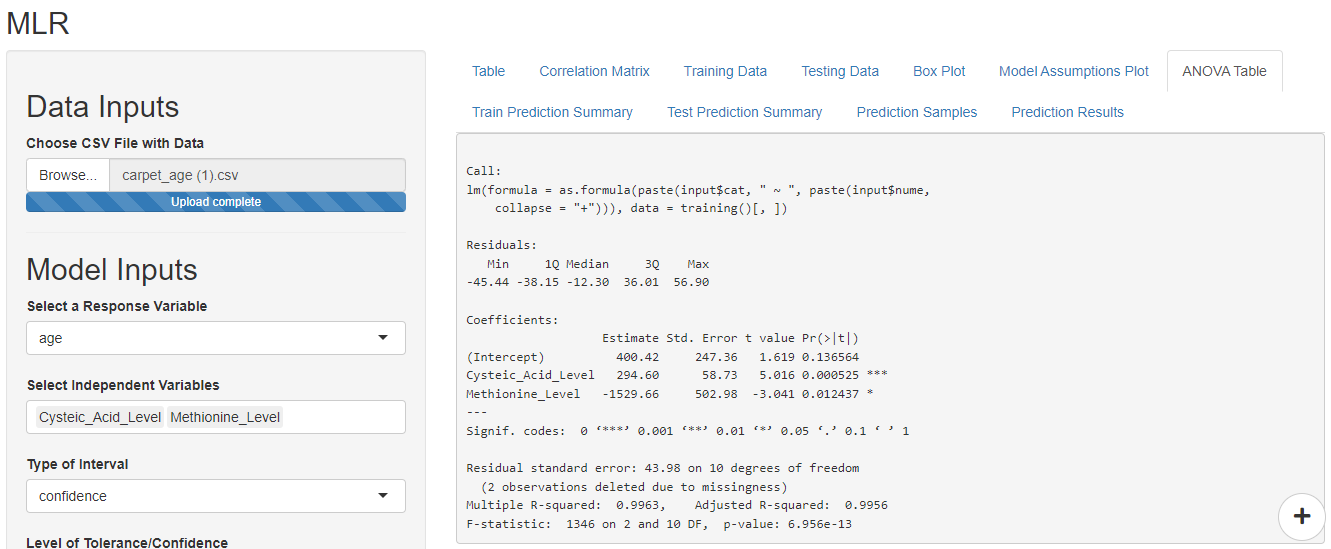
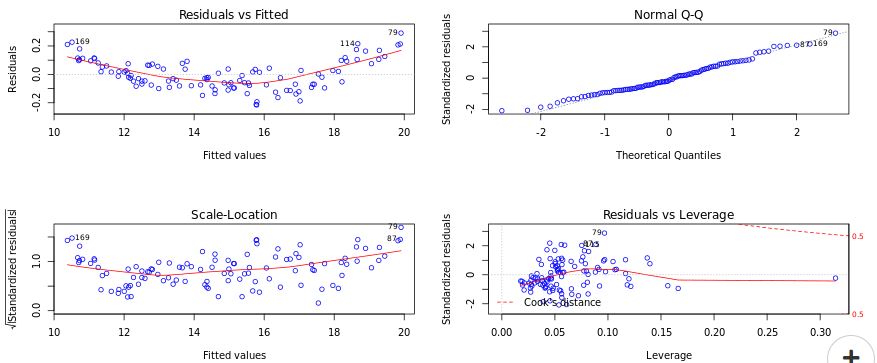
- MLR Plots: A MLR (Multiple Linear Regression) plot is a type of data visualization used in statistics and data science to visualize the relationship between a dependent variable and one or more independent variables. The plot represents the relationship between the variables in a two-dimensional space, allowing for the visual comparison and analysis of the relationships between variables. The MLR plot can be used to identify patterns, trends, and outliers in the data, and to validate the assumptions of linear regression models. The plot is a useful tool for exploring the structure of a dataset, and for improving the accuracy of regression models used for prediction and forecasting.
- WordCloud: A word cloud is a type of data visualization that displays the frequency of words in a text document as a cloud of words, where the size of each word represents its frequency. Word clouds are used to quickly identify the most frequently used words in a text, providing a visual representation of the overall theme and content of the text. They can be used in various fields such as social media analysis, sentiment analysis, content marketing, and text mining to understand the most important topics and trends in large amounts of unstructured text data. Word clouds are simple to create, easily interpretable, and provide a quick overview of the most important themes in a text.
Chart.js is a free, open-source JavaScript library for data visualization, which supports eight chart types: bar, line, area, pie (doughnut), bubble, radar, polar, and scatter. Although it is intended to be user-friendly and straightforward, it has the power to create intricate visualizations. It offers a broad variety of chart formats, including bar charts, line charts, pie charts, scatter plots, and many more. Since Chart.js is open-source, it can be used in both personal and professional projects without any limitations. In 2013, London-based web developer Nick Downie created the library, which is now community-maintained and is the second-most popular JavaScript charting library on GitHub by the number of stars, behind D3.js, despite being less customizable. Chart.js is regarded as one of the best data visualization libraries and renders in HTML5 canvas. It is offered with the MIT licence. Here are some of the features of Chart.js :
- Features : There are several commonly used chart kinds, plugins, and customization options available with Chart.js. In addition to a respectable selection of built-in chart kinds, you can utilise extra chart types that are maintained by the community. Additionally, a mixed chart can be created by combining other chart types (essentially, blending multiple chart types into one on the same canvas). Chart.js offers a wide range of customization options, including plugins for adding zoom, drag-and-drop functionality, and annotations.
- Standard Configuration : Chart.js has a solid default configuration that makes it simple to get started and create a finished, production-ready app. Even if you don’t provide any options at all, there’s a good chance you’ll still get a pretty attractive chart. For instance, Chart.js has animations enabled by default, allowing you to draw attention to the data’s narrative right away.
- Multiple Integrations : Chart.js is compatible with all well-known JavaScript frameworks, including React, Vue, Svelte, and Angular, and it has built-in TypeScript typings. You have the option of using Chart.js directly or making use of well-maintained wrapper packages that enable a more natural interaction with your preferred frameworks.
- Higher Developer Experience : More than 11,000 queries have the tag “chart.js” on Stack Overflow, GitHub Discussions, and Slack, where maintainers and community members avidly participate in discussions.
- Canvas rendering : Unlike several other, primarily D3.js-based, charting libraries, which render as SVG, Chart.js renders chart elements on an HTML5 canvas. Chart.js is incredibly fast thanks to canvas rendering, especially when dealing with large datasets and intricate visualizations that would otherwise require thousands of SVG nodes in the DOM tree. However, canvas rendering forbids CSS styling, so you must use built-in options or develop a custom plugin or chart type to render everything as you prefer.
- Smarter Performance : Large datasets work very well with Chart.js. You can avoid data parsing and normalisation by effectively ingesting such datasets using the internal format. As an alternative, the dataset can be configured to be sampled and shrunk before rendering. In the end, compared to SVG rendering, Chart.js’ canvas rendering is less demanding on your DOM tree. Additionally, tree-shaking support enables you to include only a small portion of the Chart.js code in your bundle, thereby minimising the bundle’s size and speeding up page load times.
Bokeh is a Python data visualization package that offers fast interactive charts and graphs. Bokeh output is available in a variety of formats, including notebook, html, and servers. Apps written in Django and Flask can incorporate bokeh plots. For developing interactive visualizations for contemporary web browsers like Jupyter Notebook and Refinitiv CodeBook, use the Bokeh Python package. It enables users to generate attractive plots and charts that are ready to use almost without much fiddling. Since 2013, Bokeh has been in existence. It aims to deliver dynamic visualizations rather than static images in modern web browsers. Bokeh offers libraries for several different programming languages, including Python, R, Lua, and Julia. These libraries generate JSON data that is used by the Javascript library BokehJS to build interactive visualizations that can be viewed in current web browsers. Here are some extensive features of Bokeh :
- Flexible : Common plots can be easily created with Bokeh, but it can also handle unique or specialised use-cases.
- Interactive : Devices and tools enabling you to explore “what if” scenarios or delve down into the specifics of your data with your audience.
- Shareable : Plots, dashboards, and applications can be published as Jupyter notebooks or web pages.
- Productive : Utilize all of the PyData tools you are already familiar with while working in Python.
- Powerful : To handle complex or niche instances, you may always add your own JavaScript.
- Open Source : Everything is BSD licenced and accessible on GitHub, including the Bokeh server.
- Simple to complex visualizations : Bokeh offers a variety of user interfaces that cater to users of all skill levels. Users have a choice between using basic interfaces for quick, simple visualizations and sophisticated interfaces for more involved, highly customizable visualizations.
- Support several output mediums : Jupyter Notebook and other contemporary web browsers are capable of displaying Bokeh’s output. Additionally, the output can be exported as an HTML file. Additionally, Bokeh allows for the development of interactive web applications that are run on the Bokeh server.
Java was used to create the visualization tool Gephi. It is primarily used to visualise, manipulate, and explore networks and graphs made from raw edge and node graph data. It is an open-source programme that is available for free. It is constructed on top of the Netbeans Platform and uses OpenGL as its visualization engine. It functions on Windows, Mac OS X, and Linux. For those interested in data science and graph exploration, it is a great tool. Although it works with graph data, it is comparable to Photoshop. In order to uncover hidden patterns, the user interacts with the representation and modifies the structures, shapes, and colours.The main objective is to make it possible for the user to form an opinion, find unnoticed patterns, and identify structural singularities and flaws while sourcing data.
- Real-time Visualization of Data Network : Gephi provides live data and connection visualization. For pattern recognition, especially in big graphs, this is helpful. Additionally, the app allows you to add and modify 100,000 nodes and 1,000,000 edges, which makes it a good choice for big data analysis.
- Layout Algorithm and Customization : You can also alter the graph’s design using Gephi. An algorithm for the app’s layout automatically connects the data you enter to one another and arranges it in a specific form or shape. The algorithm is created in a way that maximises the shape for readability of the graph. But you can easily alter it through the settings if you want it to take on a different shape.
- Metrics and Statistics : A metrics system and statistics framework enable you to analyse data more quickly and thoroughly. It contains metrics for social network analysis (SNA), including shortest path, diameter, modularity, clustering coefficient, and pagerank. These metrics give you a clearer visual representation and a deeper comprehension of your data. Additionally, it has a data lab where you can store, search for, and work with your data using a user interface similar to Excel. The data laboratory will be simple to use for those with spreadsheet experience.
- Data Export : You can export your data and network visualization from Gephi in PNG, PDF, or SVG formats. Prior to exporting, you can also preview your data using the vectorial preview module. You can save presets on the app to increase your productivity. Check out this article on the best tool for gathering, processing, and gaining insights to increase your knowledge of data analysis software.
- Dynamic filtering : Using the network’s structure or data, filter the network to choose specific nodes and/or edges. Use an interactive user interface to instantly filter the network.
RAWGraphs is an open source data visualization framework created with the intention of making it simple for anyone to visualise complex data. RAWGraphs is a spreadsheet application designed primarily for designers and visualization enthusiasts that aims to bridge the gap between vector graphics editors and spreadsheet programmes like Microsoft Excel, Apple Numbers, and OpenRefine (e.g. Adobe Illustrator, Inkscape, Sketch). DensityDesign Lab, working with Calibro, has been maintaining the project since its inception in 2013. RAWGraphs supports both copied and pasted text from other programmes (such as Microsoft Excel, TextWrangler, TextEdit,…) and delimiter-separated values (i.e. csv and tsv files). Visualizations based on the svg format can be quickly edited with vector graphics programmes for additional refinement or immediately embedded into web pages.
Here are some of the features :
- Open and free : As designers and/or developers working with data visualization, we must admit that without the existence of various free and open source solutions, our job would undoubtedly be very different. We consider a number of already-existing projects, such as Gephi, Open Refine, D3js, or Scriptographer, which we were able to utilise for free and which influenced our work methods and technical expertise. We wanted to give something back by enabling individuals to experiment with visualization and improve their data literacy for nothing.
- Privacy Maintained : Although RAWGraphs Visualization is a web application, only the web browser will process the data you enter. Nobody will see, touch, or copy your data because no server-side actions or storages are used.
- Optimized output : Your visualizations can be exported from RAWGraphs as.svg files. To alter them as you see fit, open them in your preferred vector graphics programme. No longer are PDFs or raster pictures hard to modify.
Grafana is an open source interactive data-visualization platform created by Grafana Labs that enables users to view their data through charts and graphs combined into one dashboard (or multiple dashboards!) for simpler interpretation and understanding. Regardless of where your data is stored—traditional server environments, Kubernetes clusters, different cloud services, etc.—you can query it and set alerts on your metrics. This makes it simpler for you to analyse the data, spot patterns and discrepancies, and ultimately improve the efficiency of your processes. Grafana was created on the basis of open standards and the idea that data should be available to everyone within an organisation, not just a select few.
Here are some of the features :
- Panels: Histograms and heatmaps are both used. graphs to geomaps You can visualise your data however you want with Grafana’s quick and adaptable visualization tools.
- Plugins: With Grafana plugins, you can link your teams’ resources and tools. Without requiring you to migrate or ingest your data, data source plugins connect to already-existing data sources via APIs and render the data in real time.
- Alerts: With Grafana Alerting, you can easily centralise and consolidate all of your alerts by creating, managing, and silencing them all from one straightforward user interface.
- Transformations: You can use transformations to rename, condense, combine, and calculate across various queries and data sources.
- Annotations: Add detailed events from various data sources to graphs. You can view the complete event metadata and tags by hovering over events.
- Panel editor: With a unified user interface for configuring data options across all of your visualizations, the panel editor makes it simple to configure, customize, and explore all of your panels.
- Collaborate: The foundation of effective collaboration is shared information access. enables you to quickly and easily distribute Grafana dashboard insights throughout your organization, team, and the world.
Conclusion
Data visualization is the only method that can guarantee the visual profiling of large datasets. Data visualization has become more dependable over time by becoming more flexible and robust. Users can navigate the complexities by using visualization to access data, derive useful insights, and choose an appropriate course of action.
We are aware of the significance of data visualization in business, as well as its advantages and various methods for creating visual formats. Without this crucial step, analytics cannot process any further steps. I, therefore, draw the conclusion that data visualization can be used in any industry and profession. Data visualization is also necessary because the vast majority of big, unstructured data cannot be comprehended by human brains alone. These data sets must be transformed into a format that we can easily comprehend. To identify trends and relationships, graphs and maps are essential if we are to gain understanding and reach a more accurate conclusion. The future of data visualization will continue to enable visualizers by offering solid and trustworthy tools for data journalism, self-service BI, social media integration, and mobile support.
Looking for Cloud Analytics Partner? Get in touch to explore how Lets Excel Analytics Solutions LLP can help you.