The subtle difference in ‘Correlation Vs Causation’ is very important for budding data analysts. Often we get so excited with the patterns in the data that we forget to evaluate if it is a mere correlation or if there is a definite cause. It is very easy to get carried away with the idea of giving some fascinating Insight to our clients or cross-functional teams. In this blog post, let us talk briefly about the difference between correlation and Causation.
Causation
The word Causation means that there is a cause-and-effect relationship between the variables under investigation. The cause and effect relationship causes one variable to change with change in other variables. For example, if I don’t study, I will fail the exam. Alternatively, if I study, I will pass the exam. In this simple example, the cause is ‘study,’ whereas ‘success in the exam’ is the effect.
Correlation does not imply causation
Correlation
The word correlation means a statistical relationship exists between the variables under investigation. The statistical relationship indicates that the change in one variable is mathematically related to the change in other variables. The variable with no casual relationship can also show an excellent statistical correlation. For example, my friend found out that a candidate’s success in an exam is positively correlated with the fairness of the candidate’s skin—the fairer the candidate, the better the success.
I am sure you will realize how it doesn’t make sense in the real world. My friend got carried away for sure, right?
Take a Way
Always look for Causation before you start analyzing the data. Remember, Causation and correlation can coexist at the same time. However, correlation does not imply Causation. It is easy to get carried away in the excitement of finding a breakthrough. But it is also essential to evaluate the scientific backing with more information.
So, how do you cross-check if the causation really exists? What are the approaches you take? Interested in sharing your data analysis skills for the benefit of our audience? Send us your blog post at info@letsexcel.in. We will surely accept your post if it resonates with our audience’s interest.
Need multivariate data analysis software? Apply here to obtain free access to our analytics solutions for research and training purposes!
Principal component analysis (PCA) is an unsupervised classification method. However, the PCA method in DataPandit cannot be called an unsupervised data analysis technique as the user interface is defined to make it semi-supervised. Therefore, let’s look at how to perform and analyze PCA in DataPandit with the help of the Iris dataset.
Arranging the data
There are some prerequisites for analyzing data in the magicPCA application as follows:
First, the data should be in .csv format.
The magicPCA application considers entries in the first row of the data set as column names by default.
The entries in the data set’s first column are considered row names by default.
Each row in the data set should have a unique name. I generally use serial numbers from 1 to n, where n equals the total number of samples in the data set. This simple technique helps me avoid the ‘duplicate row names error.’
Each column in the data set should have a unique name.
As magicPCA is a semi-supervised approach, you need to have a label for each sample that defines its class.
There should be more rows than the number of columns in your data.
It is preferable not to have any special characters in the column names as the special characters can be considered mathematical operations by the magicPCA algorithm.
The data should not contain variables with a constant value for all the samples.
The data should not contain too many zeros.
The data must contain only one categorical variable
Importing the data set
The process of importing the data set is similar to the linear regression example. You can use the drag and drop option or the browse option based on your convenience.
Steps in data analysis of PCA
Step 1: Understanding the data summary
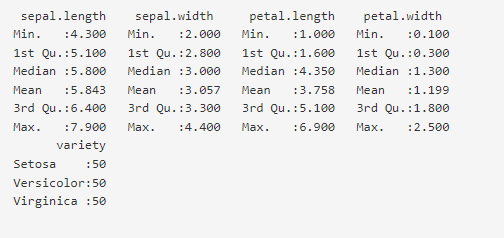
After importing the data, it makes sense to look at the minimum, maximum, mean, median, and the first and third quartile values of the data to get a feel of the distribution pattern for each variable. This information can be seen by going to the ‘Data Summary’ tab beside the ‘Data’ tab in the main menu.
Step 2: Understanding the data structure
You can view the data type for each variable by going to the ‘Data Structure’ tab beside the ‘Data Summary’ tab. Any empty cells in the data will be displayed in the form of NA values in the data structure and data summary. If NA values exist in your data, you may use data pre-treatment methods in the sidebar layout to get rid of them.
Step 3: Data Visualization with boxplot
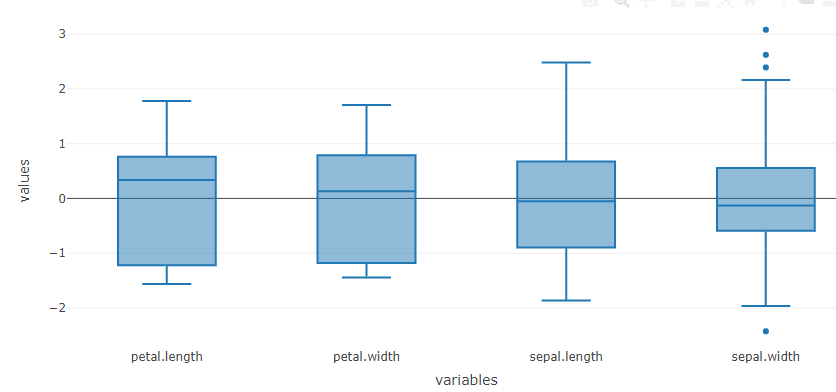
As soon as the data is imported, the boxplot for the data gets automatically populated. Boxplot can be another valuable tool for understanding the distribution pattern of variables in your data set. You can refer to our earlier published article to learn how to use boxplot.
You can mean center and scale data set to normalize the distribution pattern of the variables.
The following picture shows the Iris data when it is mean-centered.
The picture below shows the Iris data when it is scaled after mean centering.
Step 5: Divide the data in the training set and testing set
After importing the data, the training and testing data set automatically gets selected based on default settings in the application. You can change the proportion of data that goes in the training set and testing set by Increasing or decreasing the value for the ‘Training Set Probability’ in the sidebar layout, as shown in the picture below.
Suppose the value of the training set probability is increased. In that case, a larger proportion of data goes into the training set whereas, if the value is decreased, the relatively smaller proportion of data remains in the training set. For example, if the value is equal to 1, then 100% of the data goes into the training set living testing set empty.
As a general practice, it is recommended to use the training set to build the model and the testing set to evaluate the model.
Step 6: Select the column with a categorical variable
This is the most crucial step for building the PCA model using DataPandit. First, you need to select the column which has a categorical variable in it. As soon as you make a selection for the column which has a categorical variable, the model summary, plots, and other calculations will automatically appear in under the PCA section of the ‘Modal Inputs’ tab in the Navigation Panel.
Step 7: Understanding PCA model Summary
The summary of PCA can be found below the model summary tab.
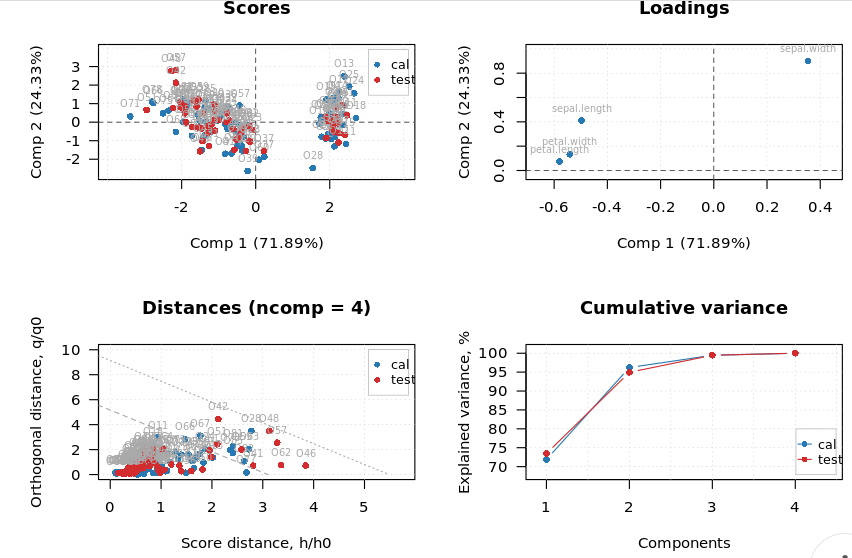
The quickest way to grasp information from the model summary is to look at the cumulative explained variance, which is shown under ‘Cumexpvar,’ and the corresponding number of components shown as Comp 1, Comp 2, Comp 3, and so on. The cumulative explained variance describes the percentage of data represented by each component. In the case of the Iris data set, the first component describes 71.89% of the data (See Expvar). At the same time, the second component represents 24.33% of the data. Together component one and component two describe 96.2 2% of the data. This means that we can replace the four variables which describe one sample in the Iris data set with these two components that describe more than 95% of the information representing that sample in the data set. And this is the precise reason why we call principal component analysis as a dimensionality reduction technique.
Step 8: Understanding PCA summary plot
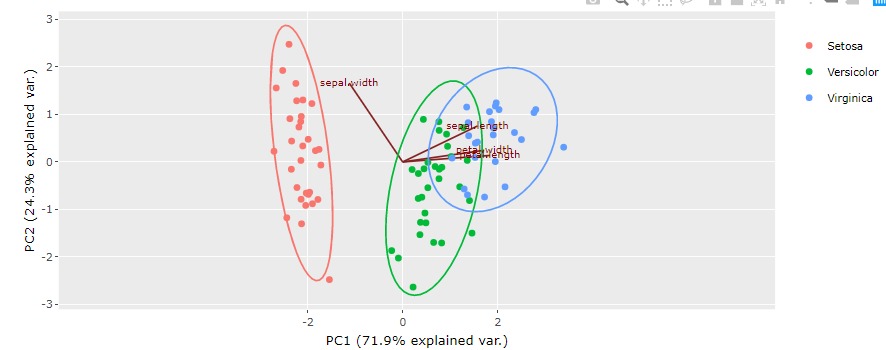
The PCA summary plot shows scores plot on the top left side, loadings plot on the top right side, distance plot on the bottom left side, and cumulative variance plot on the bottom right side. The purpose of the PCA summary plot is to give a quick glance at the possibility of building a successful model. The close association between calibration and test samples in all the plots indicates the possibility of creating a good model. The scores plot shows the distribution of data points with respect to the first two components of the model.
In the following PCA summary plot, the Scores plot shows two distinct data groups. We can use the loadings plot to understand the reason behind this grouping pattern. We can see in the loading plot that ‘sepal width’ is located father from the remaining variables. Also, it is the only variable located at the right end of the loadings plot. Therefore we can say that the group of samples located on the right side of the scores plot is associated with the sepal width variable. These samples have higher sepal width as compared to other samples. To reconfirm this relationship, we can navigate to the individual scores plot and loadings plot.
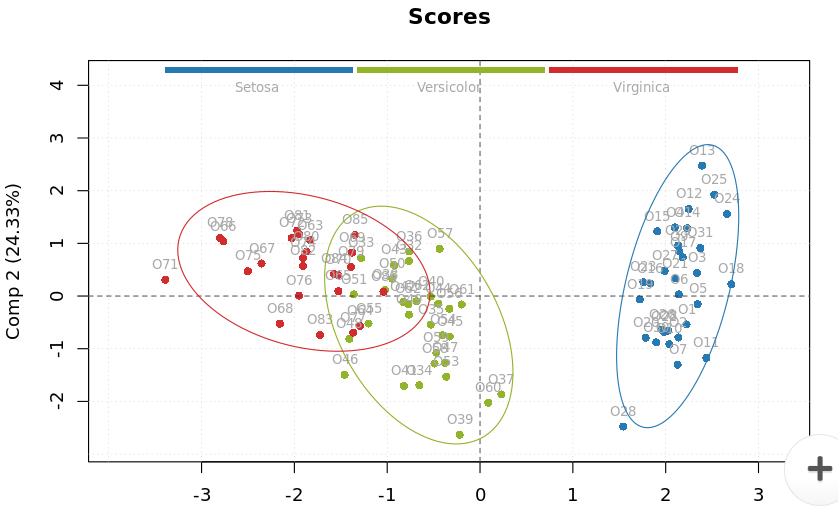
Step 9: Analyzing Scores Plot in PCA
The model summary plot only gives an overview of the model. It is essential to take a look at the individual scores plot to understand the grouping patterns in more detail. For example, in the model summary plot, we could only see two groups within the data. However, in the individual scores plot we can see three different groups within the data: setosa, versicolor, and virginica. The three groups can be identified with three different colors indicated by the legends at the top of the plot.
Step 10: Analyzing loadings plot in PCA
It is also possible to view individual loadings plot. To view it, select ‘Loadings Plot’ option under the ‘Select the Type of Plot’ in the sidebar layout.
The loadings plot will appear as shown in the picture below. If we compare the individual scores plot and loading plot, we can see that the setosa species samples are far away from the verginica and the Versicolor species. The location of the Setosa species is close to the location of sepal width on the loadings plot, which means that the setosa species has higher sepal with as compared to the other two species.
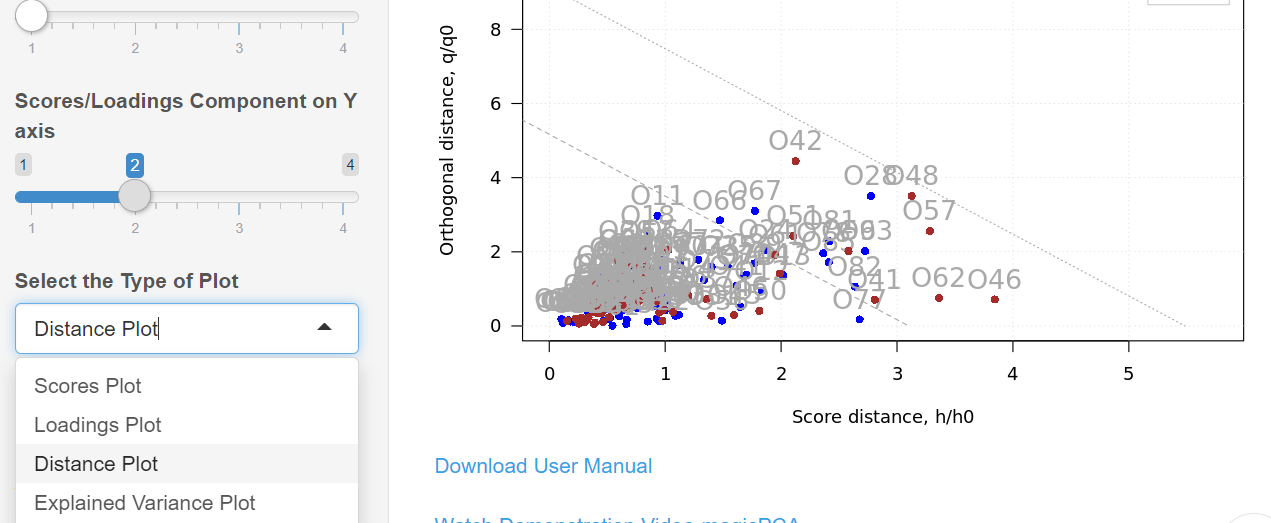
Step 11: Analyzing distance plot in PCA
You can view the distance plot by selecting the ‘Distance Plot’ option under the ‘Select the Type of Plot’ in the sidebar layout. The distance plot is used to identify outliers in the data set. If there is an outlier, it will be located far away from the remaining data points on this plot. However, the present data set does not have any outliers. Hence we could not spot any. Ideally, you should never label a sample as an outlier unless and until you know a scientific or practical reason which makes it an outlier.
Step 12: Analyzing explained variance plot in PCA
You can view explained variance plot by selecting the ‘Explained Variance Plot’ option under the ‘Select the Type of Plot’ in the sidebar layout. It shows the contribution of each principal component in describing the data points. For example, in this case, the first principal component represents 71.9 % of the data whereas the second principal component describes 24.3% of the data. This plot is used to find out the number of principal components that can optimally describe the entire data. It is expected that the optimal number of components should be lower than the total number of columns in your existing data set because the very purpose of a PCA model is to reduce the dimensionality of the data. In the case of the Iris data, we can say that two principal components are good enough to describe more than 95% of the data. Also, addition of more principal components does not result in a significant addition to the information (<5%). Pictorially, we can also come down to this conclusion by identifying the elbow point on the plot. The elbow point, in this case, is at principal component number 2.
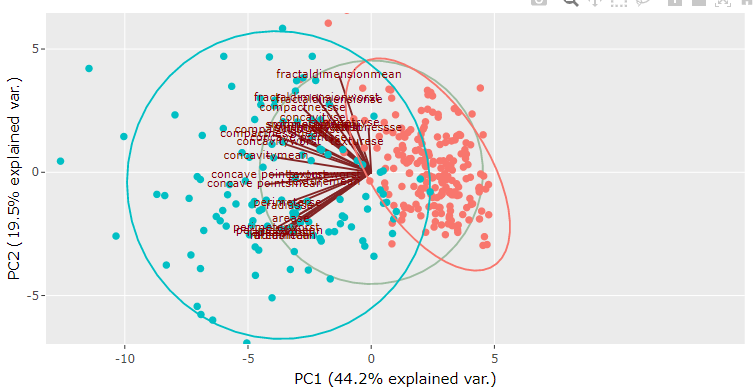
Step 13: Analyzing biplot in PCA
The biplot for PCA shows scores and the loading information on the same plot. For example, in the following plot, we can see that loadings are shown in the form of lines that originate from a common point at the center of the plot. At the same time, scores are shown as scattered points. The direction of the loadings line indicates the root cause for the location of the samples on the plot. In this case, we can see that setosa samples are located in the same direction as that of the sepal width loading line, which means that setosa species have higher sepal width than the other two species. It reconfirms our earlier conclusion drawn based on individual scores and loadings plot.
Step 14: Saving the PCA model
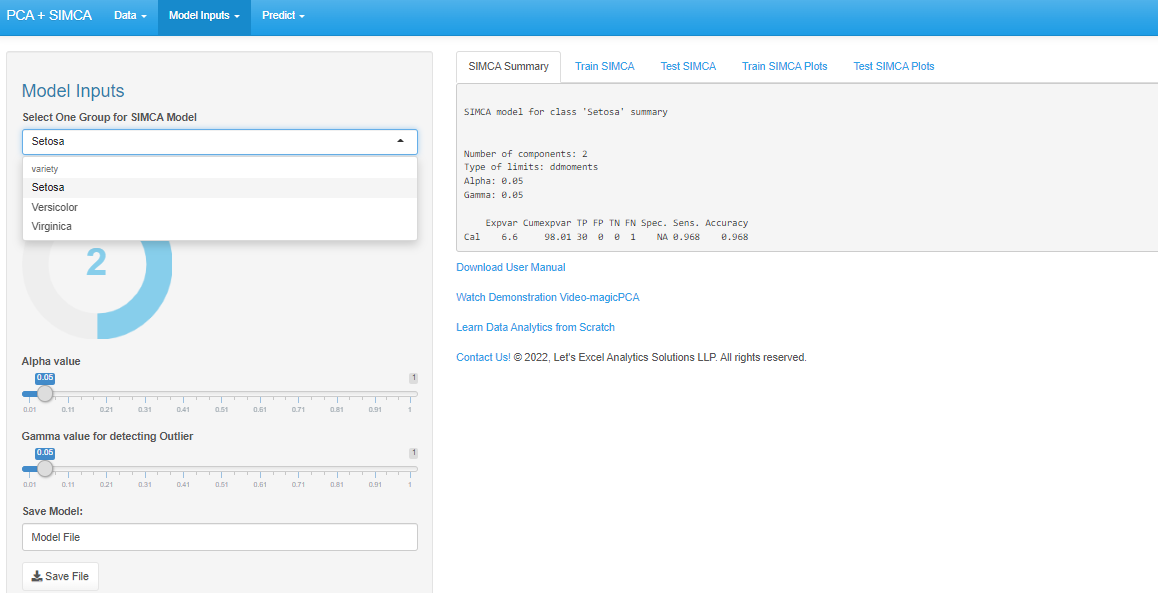
If you are satisfied with the grouping patterns in the PCA model, then you can go on to build an individual PCA model for each categorical level. Therefore, in the case of the Iris data, we need to make 3 PCA models, namely, setosa, virginica, and Versicolor. To do this, we need to navigate to the SIMCA option under the ‘Model Inputs’ option in the navigation panel.
After going to the SIMCA option, select the species for which you want to build the individual model using the drop-down menu under ‘Select One Group for SIMCA Model.’ As soon as you select one group, the SIMCA model summary appears under ‘SIMCA Summary’ in the main menu. Depending on the cumulative explained variance shown under the ‘Simca Summary’, select the number of components for SIMCA using the knob in the sidebar layout. Save individual model files for each categorical level using ‘Save File’ button under the ‘Save Model’ option in the sidebar layout.
Step 16: Uploading PCA Models for SIMCA predictions
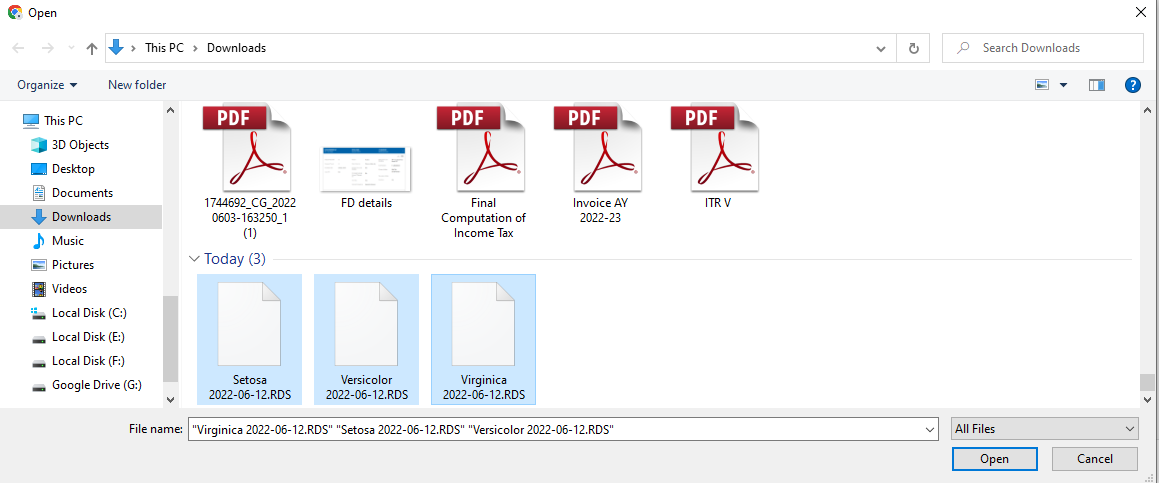
You can upload the saved individual model files using the ‘Upload Model’ feature in the sidebar layout.
To upload the model files, browse to the location of the files in your computer, select the ‘All files’ option in the browsing window, Press’ ctrl’, and select all the model files for the individual models as shown in the picture below.
Step 17: Understanding the result for the train set
As soon as the individual model files are uploaded, the predictions for the train set and test set populate automatically. Go to the ‘Train SIMCA’ tab to view the predictions for the train set . You can see the predictions for individual sample by looking at the table which displays on the screen under the ‘Train SIMCA’ tab. In the prediction table, 1 indicates the successful classification of the sample into the corresponding category represented by column name. However, it may not be convenient to check the classification of each sample in the training data. Therefore, to avoid this manual work, you can scroll down to see the confusion matrix.
The confusion matrix for the train set of Iris data is shown in the figure below. The rows of the confusion matrix represent the actual class of the sample, whereas the columns of the confusion Matrix represent the predicted class of the sample. Therefore, the quickest way to analyze the confusion matrix is to look at the diagonal elements and non-diagonal elements of the matrix. Every non-diagonal element in the confusion matrix is misclassified and contributes to the classification error. If there are more non-diagonal elements than the diagonal elements in your confusion Matrix, then that means the models cannot distinguish between different classes in your data. For example, in the case of Iris, data following confusion matrix shows that four Versicolor samples are misclassified as Verginaca, and one sample from each class could not be classified into any species. The model’s accuracy can be calculated by performing a sum of correctly classified samples and dividing it by the total number of samples in the training set. In this case, accuracy will be equal to the sum of diagonal elements divided by the total number of samples in the train set. At the same time, the misclassification error can be found by subtracting the accuracy from 1.
The closer the accuracy value to 1, the better the model’s predictability.
The Confusion Matrix can be pictorially seen by going to the ‘Train SIMCA plot’ option in the main menu. The plot shows the three species in three different colours, represented by the legend at the top.
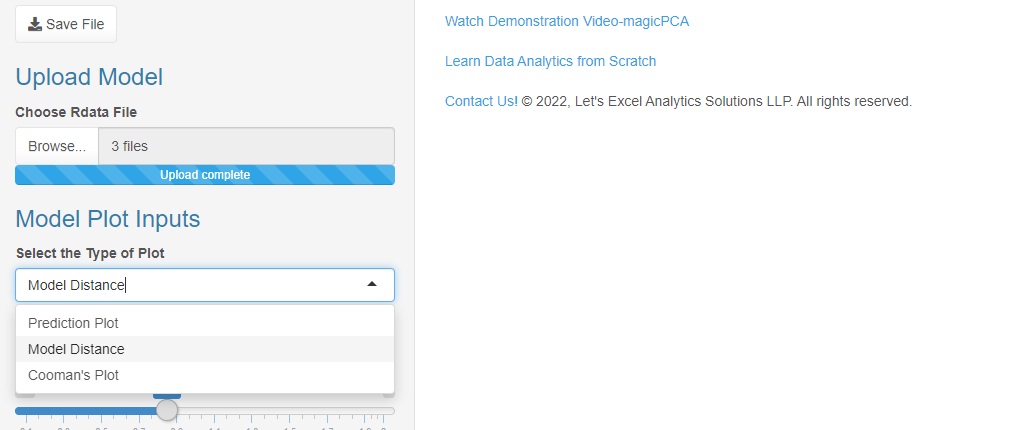
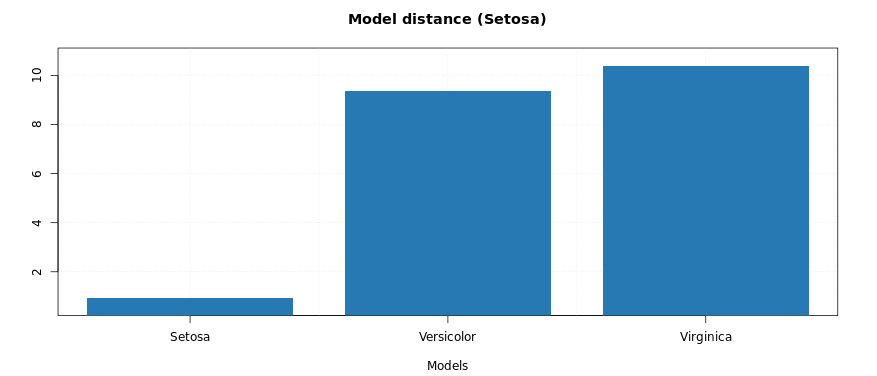
You can view cooman’s plot by selecting Cooman’s Plot’ or the ‘Model Distance Plot’ option in the ‘Model Plot Inputs’ in the sidebar layout.
Cooman’s plot shows squared orthogonal distance from data points to the first two selected SIMCA (individual PCA) models. The points are color grouped according to their respective class in the case of multiple result objects.
‘Model Distance Plot’ is a generic tool for plotting distance from the first model class to other class models.
Step 18: Understanding the result for the test set
The process of analyzing the results for the test set is the same as that of the train set. The results for the test set can be found under the ‘Test SIMCA’ and the ‘Test SIMCA Plot.’
Step 19: Predict the unknown
If you are happy with the train set and test set results, you can go ahead and navigate to the ‘Predict’ option in the Navigation Panel. Here you need to upload the file with samples from unknown class and the individual models using the process similar to step 16. And the Prediction Plot will populate automatically.
Conclusion
Principal Component Analysis is a powerful tool for material characterization, root cause identification, and differentiating between the groups in the data. In addition, DataPandit’s magicPCA makes it possible to predict of the unknown class of data with the help of a dataset with known classes of samples.
Need multivariate data analysis software? Apply here for free access to our analytics solutions for research and training purposes!
Whenever you come across a few variables that seem to be dependent on each other, you might want to explore the linear regression relationship between the variables. linear regression relationship can help you assess:
The strength of the relationship between the variables
Possibility of using predictive analytics to measure future outcomes
This article will discuss how linear regression can help you with examples.
Advantages of linear regression
Establishing the linear relationship can be incredibly advantageous if measuring the response variables is either time-consuming or too expensive. In such a scenario, linear regression can help you make soft savings by reducing the consumption of resources.
Linear regression can also provide scientific evidence for establishing a relationship between cause and effect. Therefore the method is helpful in submitting evidence to the regulatory agencies to justify your process controls. In the life-science industry, linear regression can be used as a scientific rationale in the quality by design approach.
Types of linear regression
There are three major types of linear regression as below:
Simple linear regression: Useful when there is one independent variable and one dependent variable
Multiple linear regression: Useful when there are multiple independent variables and one dependent variable
Both types of linear regression methods mentioned above need to meet assumptions for Linear regression. You can find these assumptions in our previous article here.
This article will see one example of simple linear regression and one example of multiple linear regression.
Simple linear regression
To understand how to model the relationship between one independent variable and one dependent variable, let’s take the simple example of the BMI dataset. We will explore if there is any relationship between the height and weight of the individuals. Therefore, our Null hypothesis is that ‘There is no relationship between weight and height of the individuals’.
Step I
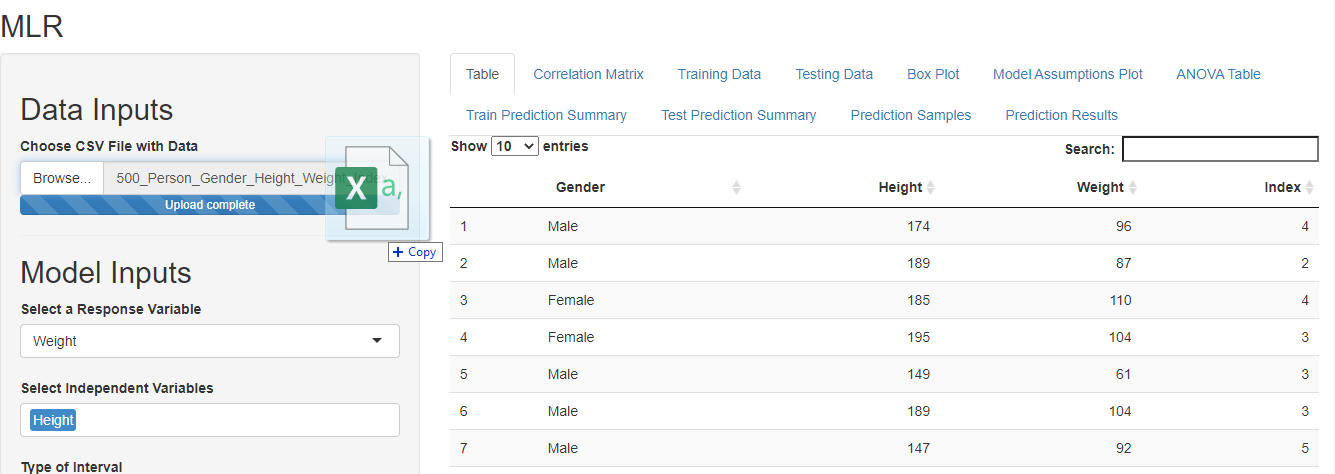
Let’s start by Importing the data. To do this drag and drop your data in the Data Input fields. You can also browse to upload data from your computer.
DataPandit divides your data into train set and test set using default settings where (~59%) of your data gets randomly selected in the train set and the remaining goes into the test set. You have the option to change these settings in the sidebar layout. If your data is small you may want to increase the value higher than 0.59 to include more samples in your train set.
Step II
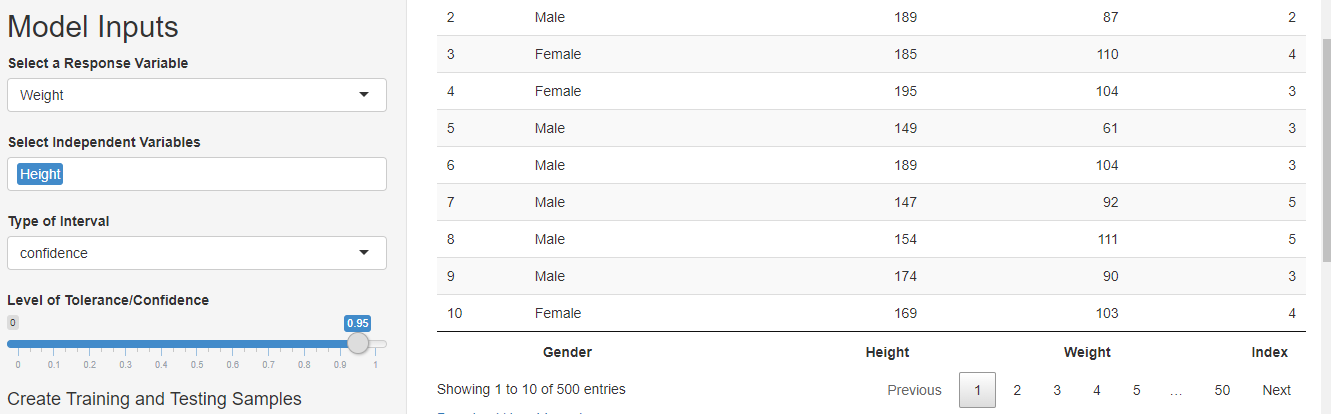
The next step is to give model inputs. Select the dependent variable as the response variable and the independent variable as the predictors. I wanted to use weight as a dependent variable and height as an independent variable hence I made the selections as shown in the figure below.
Step III
Next refer to articles for Pearson’s correlations matrix, box-plots, and models assumptions plot for pre-modeling data analysis. In this case, Pearson’s correlation matrix for two variables won’t display as it is designed for more than two variables. However, if you still wish to see it you can select the height and weight both as independent variables and it will display. After you are done, just remove weight from the independent variables to proceed further.
Step IV
The ANOVA table displays automatically as soon as you select the variables for the model. Hence, after the selection of variables you may simply check the ANOVA table by going to the ANOVA Table tab as shown below:
The p-value for Height in the above ANOVA table is greater than 0.05 which indicates that there are no significant differences in weights of individuals with different heights. Therefore, we fail to reject the null hypothesis. The R squared value and Adjusted R Squared value are also close to zero indicating that the model may not have a high prediction accuracy. The small F- statistic also supports the decision to reject the null hypothesis.
Step V
If you have evidence of a significant relationship between the two variables, you can proceed with train set predictions and test set predictions. The picture below shows the train set predictions for the present case. You can consider this as a model validation step where you evaluating the accuracy of predictions. You can select confidence intervals or prediction intervals in the sidebar layout to understand the range in which future predictions may lie. If you are happy with the train and test predictions you can save your model using the ‘save file’’ option in the sidebar layout.
Step VI
It is the final step in which you use the model for future prediction. In this step you need to upload the saved file using the Upload Model option in the sidebar layout. Then you need to add the data of predictors for which you want to predict the response. In this case, you need to upload the CSV file with the data for the model to predict weights. While uploading the data to make predictions for unknown weights, please ensure that you don’t have the weights column in your data.
Select the response name as Weight and the predictions will populate along with upper and lower limits under the ‘Prediction Results’ tab.
Multiple linear regression
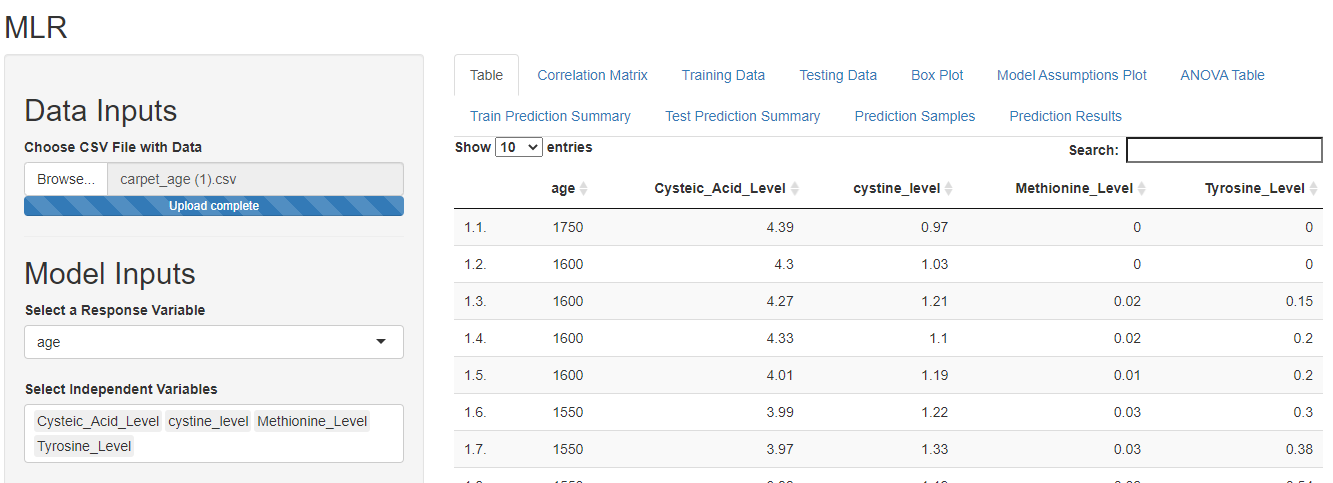
The steps for multiple regression are the same as that of Simple linear regression except that you can choose multiple variables as independent variables. Let’s take an example of detection of the age of carpet based on Chemical levels. The data contains the Age of 23 Old Carpet and Wool samples, along with corresponding levels of chemicals such as Cysteic Acid, Cystine, Methionine, and Tyrosine.
Step I
Same as simple linear regression.
Step II
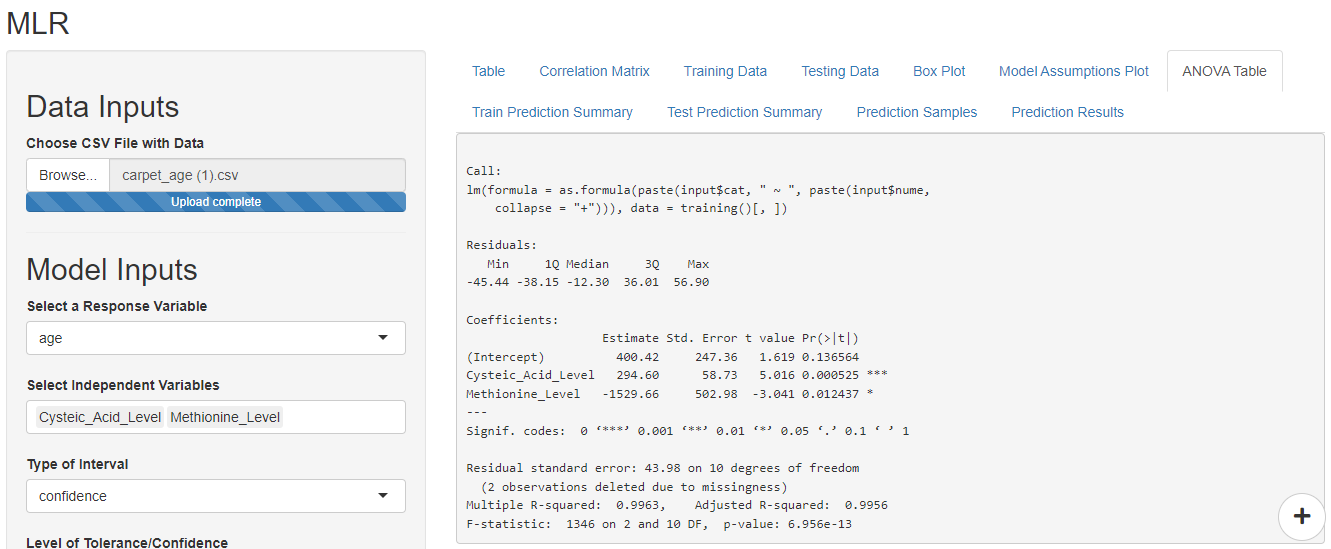
In this case, we wish to predict the age of the carpet hence, select age as the response variable. Select all other factors as independent variables.
Step III
Same as simple linear regression.
Step IV
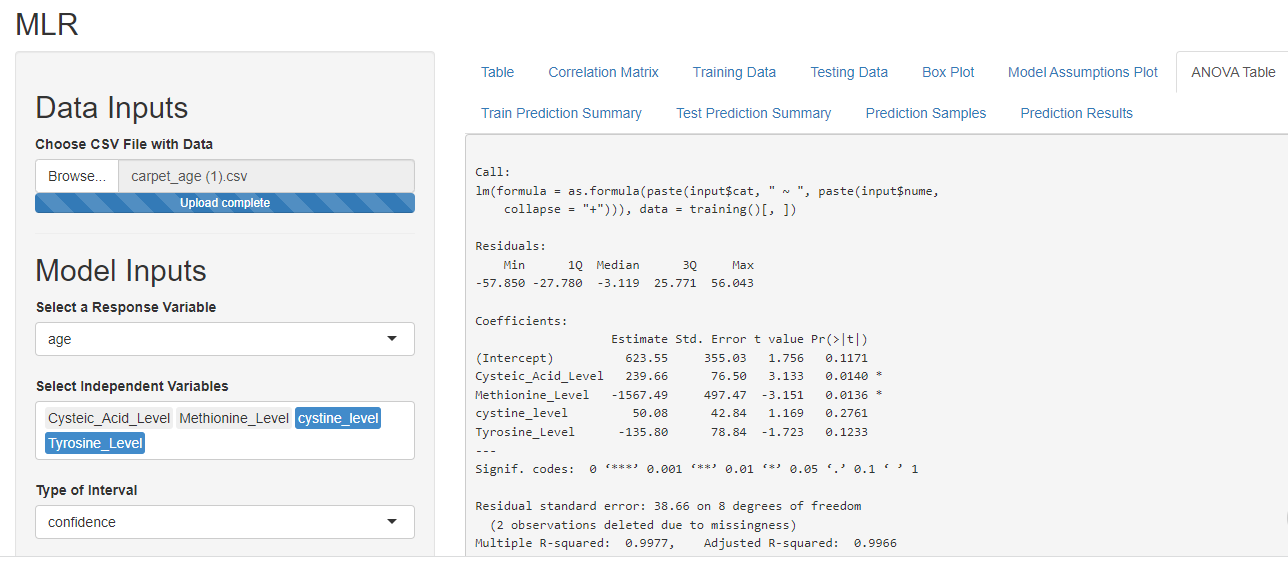
The cystine level and tyrosine level do not have a significant p-value hence they can be eliminated from the selected independent variables to improve the model.
The Anova table automatically updates as soon as you make changes in the ‘Model Inputs’. Based on the p-value, F-statistic, multiple R-square and adjusted R square the model shows a good promise for making future predictions.
Step V
Same as simple linear regression.
Step VI
Same as simple linear regression.
Conclusion
Building linear regression models with DataPandit is a breeze. All you need is well-organized data with a strong scientific backing. Because correlation does not imply causation!
Need multivariate data analysis software? Apply here to obtain free access to our analytics solutions for research and training purposes!
The theory of linear regression is based on certain statistical assumptions. It is crucial to check these regression assumptions before modeling the data using the linear regression approach. In this blog post, we describe the top 7 assumptions and you should check in DataPandit before analyzing your data using linear regression. Let’s take a look at these assumptions one by one.
#1 There is a Linear Model
The constant terms in a linear model are called parameters whereas the independent variable terms are called predictors for the model. A model is called linear when its parameters are linear. However, it is not necessary to have linear predictors to have a linear model.
To understand the concept, let’s see how a general a linear model can be written? The answer is as follows:
In the above example, it is possible to obtain various curves by transforming the predictor variables (Xs) using power transformation, logarithmic transformation, square root transformation, inverse transformation, etc. However, the parameter must remain linear always. For example, the following equation represents a linear model because the parameters ( b o,b1, andb2)are linear and only X1 is raised to the power of 2.
Y = b o + b1X1 + b2X12
In DataPandit the algorithm automatically picks up the linear model when you try to build a linear or a multiple linear regression relationship. Hence you need not check this assumption separately.
#2 There is no multicollinearity
If the predictor variables are correlated among themselves, then the data is said to have a multicollinearity problem. In other words, if the independent variable columns in your data set are correlated with each other, then there exists multicollinearity within your data. In DataPandit we use Pearson’s Correlation Coefficient to measure the multicollinearity within data. The assumption of no multicollinearity in the data can be easily visualized with the help of the collinearity matrix.
Figure 1: High level of multicollinearity in the dataFigure 2: No multicollinearity in the data
#3 Homoscedasticity of Residuals or Equal Variances
The linear regression model assumes that there will be always some random error in every measurement. In other words, no two measurements are going to be exactly equal to each other. The constant parameter (b o ) in the linear regression model represents this random error. However linear regression model does not account for systematic errors which may occur during a process.
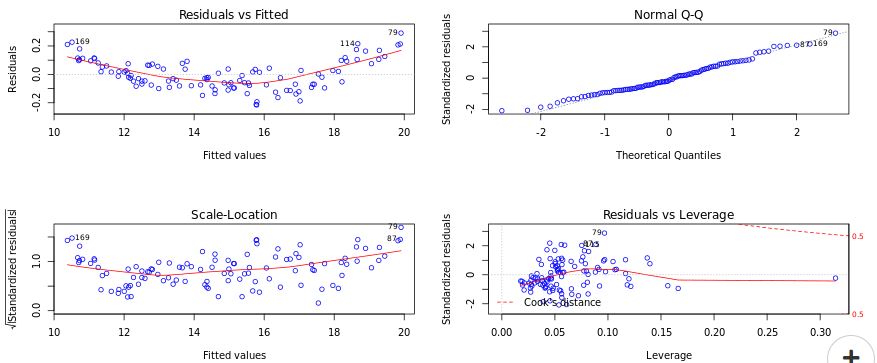
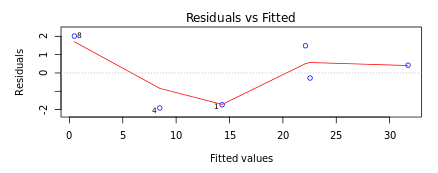
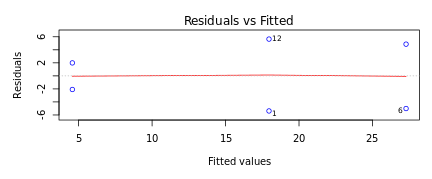
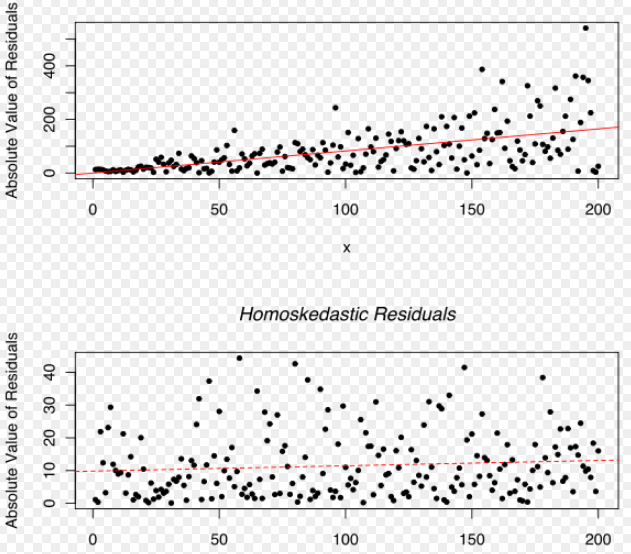
Systematic error is an error with a non-zero mean. In other words, the effect of the systematic error is not reduced when the observations are averaged. For example, loosening of upper and lower punches during the tablet compression process results in lower tablet hardness over a period of time. The absence of such an error can be determined by looking at the Residuals versus fitted values plot in DataPandit. In presence of systematic error, the residuals Vs Fitted values plot will look like Figure 3.
If the Residuals are equally distributed on both sides of the trend line in the residual versus fitted values plot as in Figure 4, then it means there is an absence of systematic error. The idea is that equally distributed residuals or equally distributed variances will average out themselves to zero. Therefore, one can safely assume that measurements only have a random error that can be accounted for by the linear model and there is the absence of systematic error.
Figure 3: Residuals Vs Fitted Exhibiting HeteroscedasticityFigure 4: Residuals Vs Fitted Exhibiting Homoscedasticity
#4 Normality of Residuals
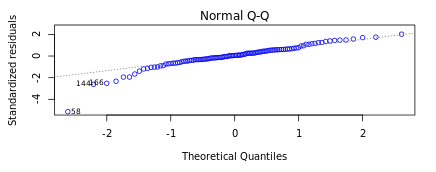
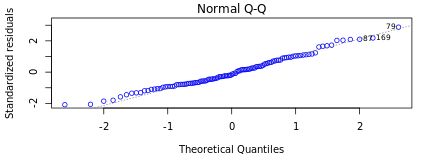
It is important to confirm the normality of residuals for reaffirming the absence of systematic errors as stated above. It is assumed that if the residuals are normally distributed they are unlikely to have an external influence (systematic error) that will cause them to increase or decrease consistently over a period of time. In DataPandit you can check the assumption for normality of residuals by looking at the Normal Q-Q plot.
Figure 5 and Figure 6 demonstrate the case when the assumption of normality is not met and the case when the assumption of normality is met respectively.
Figure: 5 Residuals do not follow Normal DistributionFigure 6: Residuals follow Normal Distribution
#5 Number of observations > number of predictors
For a minimum viable model,
Number of observations= Number of Predictors + 1
However greater the number of observations better the model performance. Therefore, to build a linear regression model you must have more observations than the number of independent variables (predictors) in the data set.
For example, if you are interested in predicting the density based on mass and volume, then you must have data from at least three observations because in this case, you have two predictors namely, mass and volume.
#6 Each observation is unique
It is also important to ensure that each observation is independent of the other observation. Meaning each observation in the data set should be recorded/measured separately on a unique occurrence of the event that caused the observation.
For example, if you want to include two observations to measure the density of a liquid with 2 Kg mass and 2 l volume, then you must perform the experiment twice to measure the density for the two independent observations. Such observations are called replicates of each other. It would be wrong to use same measurement for both observations, as you will disregard the random error.
#7 Predictors are distributed Normally
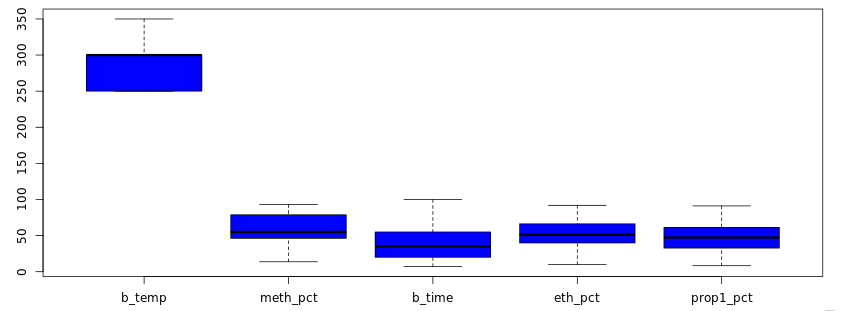
This assumption ensures that you have evenly distributed observations for the range of each predictor. For example, if you want to model the density of a liquid as a function of temperature, then it will make sense to measure the density at different temperature levels within your predefined temperature range. However, if you make more measurements at lower temperatures than at higher temperatures then your model may perform poorly in predicting density at high temperatures. To avoid this problem it will make sense to take a look at the boxplot for checking the normality of predictors. Read this article to know how boxplots can be used to evaluate the normality of variables. For example, in Figure 7, all predictors except ‘b-temp’ are normally distributed.
Figure 7: Checking Normality assumption for the predictors
Closing
So, this was all about assumptions for linear regression. I hope that this information will help you to better prepare yourself for your next linear regression model.
Need multivariate data analysis software? Apply here to obtain free access to our analytics solutions for research and training purposes!
Data visualization is the first step in data analysis. DataPandit allows you to visualize boxplots as soon as you segregate categorical data from numerical data. However, the box plot does not appear until you uncheck ‘Is this spectroscopic data?’ option in the sidebar layout, as shown in Figure 1.
Figure 1: Boxplot in DataPandit
The box plot is also known as ‘Box – Whisker Plot’. It provides 5-point information, including the minimum score, first (lower) quartile, median, third (upper) quartile, and maximum score.
When Should You Avoid Boxplot for Data Visualization?
The box plot itself provides 5-point information for data visualization. Hence, you should never use a box plot to visualize data with less than five observations. In fact, I would recommend using a boxplot only if you have more than ten observations.
Why Do You Need Data Visualization?
If you want a DataPandit user, you might just ask, ‘Why should I visualize my data in first place? Wouldn’t it be enough if I just analyze my model by segregating the response variable/categorical variable in the data?’ The answer is, ‘No’ as data visualization is the first step before proceeding to data modeling. Box plots often help you determine the distribution of your data.
Why is Distribution Important for Data Visualization?
If your data is not normally distributed, you most likely might induce bias in your model. Additionally, your data may also have some outliers that you might need to remove before proceeding to advanced data analytics approaches. Also, depending on the data distribution, you might want to apply some data pre-treatments to build better models.
Now the question is how data visualization can help to detect these abnormalities in the data? Don’t worry, we will help you here. Following are the key aspects that you must evaluate while data visualization.
Know the spread of the data by using a boxplot for data visualization
Data visualization can help you determine the spread of the data by looking at the lowest and highest measurement for a particular variable. In statistics, the spread of the data is also known as the range of the data. For example, in the following box plot, the spread of the variable ‘petal.length’ is from 1 to 6.9 units.
Figure 2: Iris raw data boxplot
Know Mean and Median by using a boxplot for data visualization
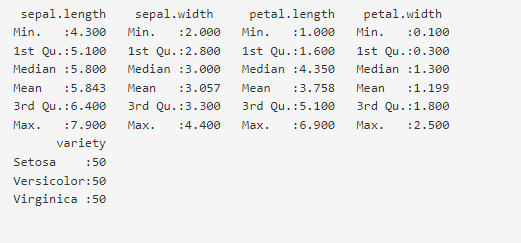
Data visualization with boxplot can help you quickly know the mean and median of the data. The mean and median of normally distributed data coincide with each other. For example, we can see that the median petal.length is 4.35 units based on the boxplot. However, if you take a look at the data summary for the raw data, then the mean for petal length is 3.75 units as shown in Figure 3. In other words, the mean and median do not coincide which means the data is not normally distributed.
Figure 3: Data summary for Iris raw data
Know if your data is Left Skewed or Right Skewed by using boxplot for data visualization
Data visualization can also help you to know if your data is skewed using the values for mean and median. If the mean is greater than the median, the data is skewed towards the right. Whereas if the mean is smaller than the median, the data is skewed towards the left.
Alternatively, you can also observe the interquartile distances visually to see where most of your data lie. If the quartiles are uniformly divided, you most likely have normal data.
Understanding the skewness can help you know if the model will have a bias on the lower side or higher side. You can include more samples to achieve normal distribution depending on the skewness.
Know if the data point is an outlier by using a boxplot for data visualization
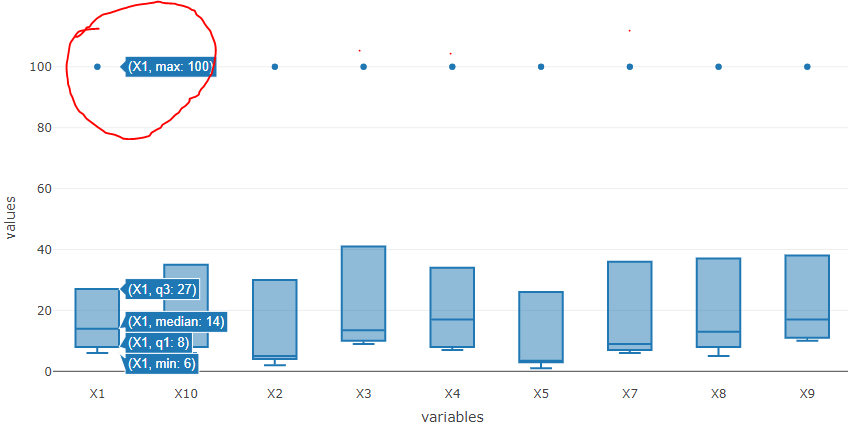
Data visualization can help identify outliers. You can identify outliers by looking at the values far away from the plot. For example, the highlighted value (X1, max=100) in Figure 4 could be an outlier. However, in my opinion, you should never label an observation as an outlier unless you have a strong scientific or practical reason to do so.
Figure 4: Spotting outlier in boxplot
Know if you need any data pre-treatments by using boxplot for data visualization
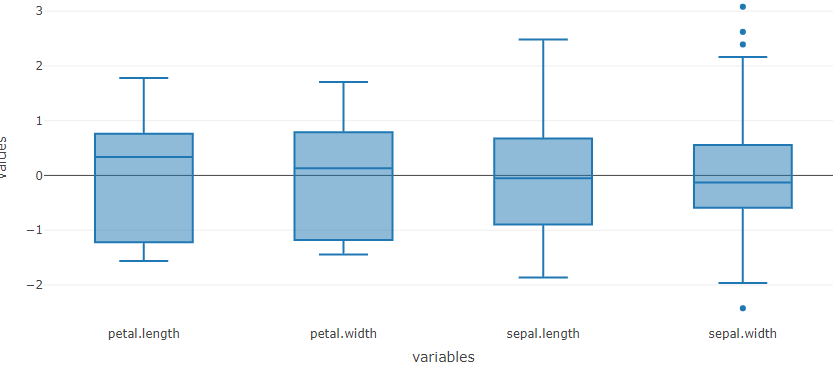
Data visualization can help you know if your data needs If the data spread is too different for different variables, or if you see outliers with no scientific or practical reasons, then you might need some data pre-treatments. For example, you can mean center and scale the data as shown in Figure 5 and Figure 6 before proceeding to the model analysis. You can see these dynamic changes in the boxplot only in the MagicPCA application.
Figure 5: Iris mean-centered data boxplotFigure 5: Iris mean-centered data boxplot
x
Conclusion
Data visualization is crucial to building robust and unbiased models. Boxplots are one of the easiest and most informative ways of visualizing the data in DataPandit. Boxplots can be a very useful tool for spotting outliers, and understanding the skewness in the data. Additionally, they can also help to finalize the data pre-treatments for building robust models.
Need multivariate data analysis software? Apply here to obtain free access to our analytics solutions for research and training purposes!
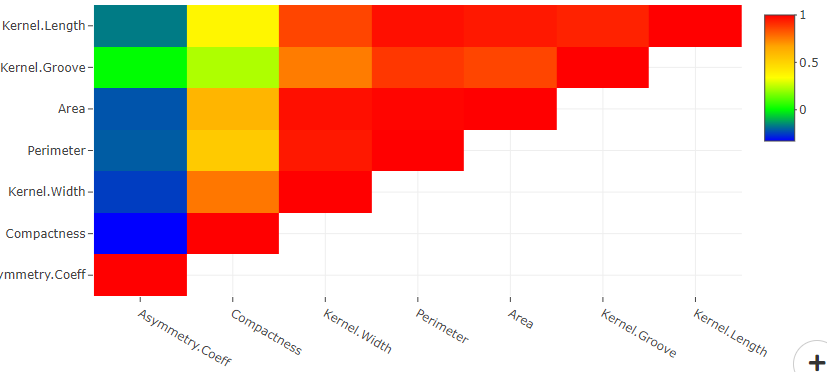
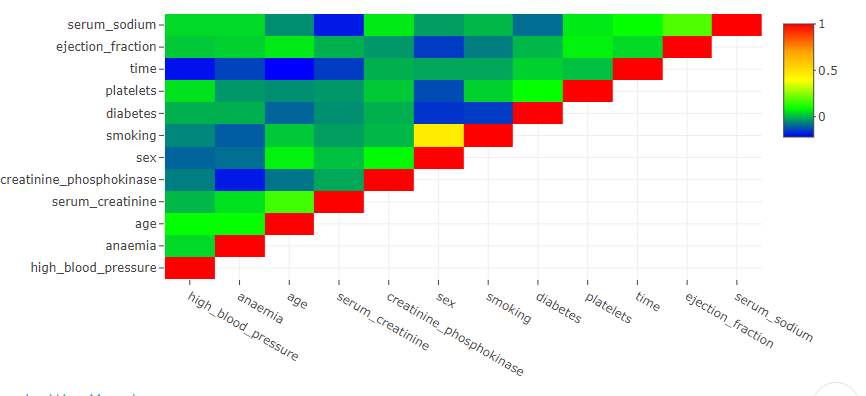
The correlation matrix in DataPandit shows the relationship of each variable in the dataset with every other variable in the dataset. It is basically, a heatmap of Pearson correlation values between corresponding variables.
For example, in the correlation matrix above, the first element on X-axis is high_blood_pressure while that on the Y-axis is high_blood_pressure too. Therefore, it should show a Perfect correlation with itself with Pearson’s correlation coefficient value of 1. If we refer to the legend at the top right side of the correlation matrix, we can see that Red Color shows the highest value (1) in the heatmap while the blue color shows the lowest value in the heatmap. Theoretically, the lowest possible value for Pearson’s correlation is -1. However, the lowest value in the heatmap may vary from data to data. However, every heatmap will show the highest correlation value of 1 owing to the presence of the diagonal elements.
The diagonal elements of the correlation matrix are the relationship of each variable with itself and hence show a perfect relationship (Pearson’s Correlation Co-efficient of 1).
However, it doesn’t make much sense to see the relationship of any variable with itself. Therefore, while analyzing the correlation matrix treat these diagonal elements as points of reference.
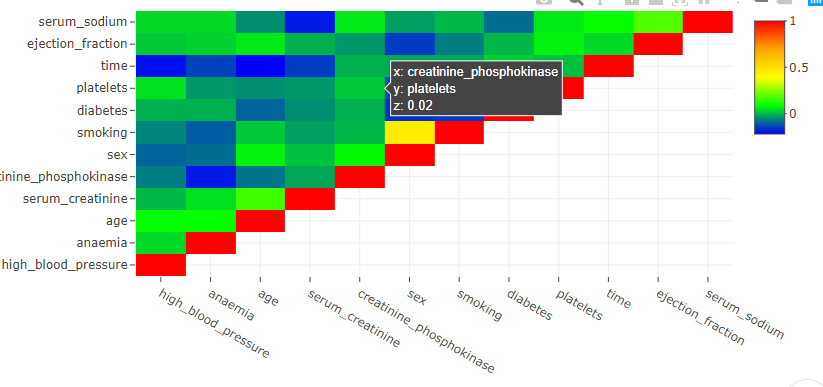
You can hover over the matrix elements to see the X and Y variable along with the numerical value of Pearson’s correlation coefficient to know the exact coordinates.
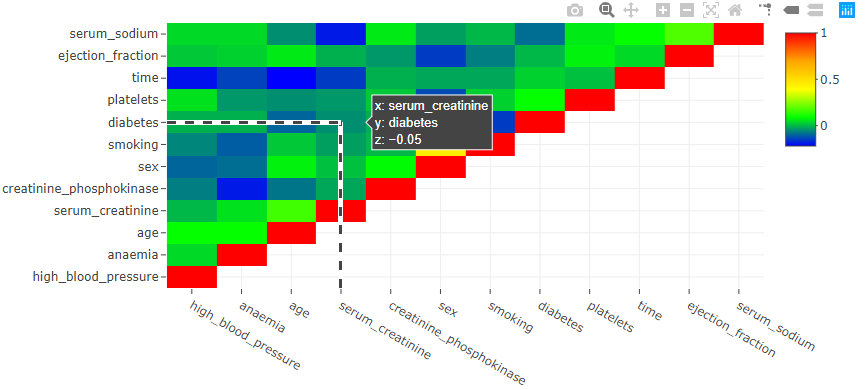
There are options to zoom in, zoom out, add toggle spikes, autoscale and save the plot at the top right corner of the plot. Toggle spikes draws perpendicular lines on the X and Y axis and shows the exact coordinates with value of Pearson’s correlation.
In the above correlation matrix, the toggled spike lines show that diabetes and serum_creatinine have a Pearson’s correlation coefficient of -0.05 indicating no relationship between the two variables.
Read our blog post here to know more about Pearson’s correlation. Apply here if you are interested in obtaining free access to our analytics solutions for research and training purposes?
Pearson’s correlation is a statistical measure of the linear relationship between two variables. Mathematically, it is the ratio of covariances of the two variables And the product of their standard deviations. Therefore the formula for Pearson’s correlation can be written as follows:
Mathematical Expression for Pearson’s Correlation
The result for Pearson’s correlation always varies between -1 and + 1. Pearson’s correlation can only measure linear relationships and it does not apply to higher-order relationships which are Non-linear in nature.
Assumptions for Pearson’s correlation
Following are the assumptions for proceeding to data analysis using Pearson’s correlation:
Independent of the case: Pearson’s correlation should be measured on cases that are independent of each other. For example, it does not make sense to measure Pearson’s correlation for the same variable measured in two different units or with the same variable itself. even if Pearson’s correlation is measured for a variable that is not independent of the other variable there is a high chance that the correlation will be a perfect correlation of 1.
Linear relationship: The relationship between two variables can be assessed for its linearity by plotting the values of variables on a scatter diagram and checking if the plot yields a relatively straight line. The picture below demonstrates the difference between the trend lines of linear relationships and nonlinear relationships.
Linear relationship Vs. Non-linear relationship
Homoscedasticity: Two variables show homoscedasticity if the variances of the two variables are equally distributed. It can be evaluated by looking at the scatter plot of Residuals. The scatterplot of the residuals should be roughly rectangular-shaped as shown in the picture below.
Homoscedasticity Vs. Heteroscedasticity
Properties of Pearson’s Correlation
Limit: Coefficient values can range from +1 to -1, where +1 indicates a perfect positive relationship, -1 indicates a perfect negative relationship, and a 0 indicates no relationship exists..
Pure number: Pearson’s correlation comes out to be a dimensionless number because of its formula. Hence its value remains unchanged even with changes in the unit of measurement. For example, if one variable’s unit of measurement is in grams and the second variable is in quintals, even then, Pearson’s correlation coefficient value does not change.
Symmetric: The Pearson’s correlation coefficient value remains unchanged for the relationship between X and Y or Y and X, hence it is called a Symmetric measure of a relationship.
Positive correlation
Pearson’s correlation coefficient indicates a positive relationship between two variables if its value ranges from 0 to 1. This means that when the value of one of the variables among the two variables increases, the value of the other variable increases too.
An example of, a positive correlation is a relationship between the height and weight of the same individual. Because naturally the increase in height is associated with the increase in length of bones of the individual, and the larger bones would contribute to the increased weight of the individual. Therefore, if Pearson’s correlation for height and weight data of the same individual is calculated, then it would indicate a positive correlation.
Negative correlation
Pearson’s correlation coefficient indicates a negative relationship between two variables if its value ranges from 0 to -1. This means that when the value of one of the variables among the two variables increases, the value of the other variable decreases.
An example of a negative correlation between two variables is the relationship between height above sea level and temperature. The temperature decreases as the height above the sea level increase therefore there exists a negative relationship between these two variables.
Degree of correlation:
The strength of the relationship between two variables is measured by the value of the correlation coefficient. The statisticians use the following degrees of correlations to indicate the relationship:
Perfect relationship: If the value is near ± 1, then there is a perfect correlation between the two variables as one variable increases, the other variable tends to also increase (if positive) or decrease (if negative).
High degree relationship: If the correlation coefficient value lies between ± 0.50 and ± 1, then there is a strong correlation between the two variables.
Moderate degree relationship: If the value of the correlation coefficient lies between ± 0.30 and ± 0.49, then there is a medium correlation between the two variables.
Low degree relationship: When the value of the correlation coefficient lies below + .29, then there is a weak relationship between the two variables.
No relationship: There is no relationship between two variables if the value of the correlation is 0.
Pearson’s Correlation in Multivariate Data Analysis
In addition to finding relationships between two variables, Pearson’s correlation is also used to understand the multicollinearity in the data for multivariate data analysis. This is because the suitability of the data analysis method depends on the multicollinearity within the data set. If there is high multicollinearity within the data then Multivariate Data Analysis techniques such as Partial Least Square Regression, Principal Component Analysis, and Principal Component Regression are most suitable for modeling the data. Whereas, if the data doesn’t show a multicollinearity problem, then it can be used for data analysis using multiple linear regression and linear discriminant analysis. That is the reason why you should take a good look at your Pearson correlation Matrix while choosing data analytics models using the DataPandit platform. Read this article to know more about how to use the correlation matrix in DataPandit.
Conclusion
Pearson’s correlation coefficient is an important measure of the strength of the relationship between two variables. Additionally, it can be also used to assess the multicollinearity within the data.
Did you know that Let’s Excel Analytics Solutions provides free access to its analytics SaaS applications for research and training purposes? All you have to do is fill up this form if you are interested.
Last week I met John, a process expert who works at a renowned cosmetic manufacturing company. John was pretty frustrated over a data scientist who could not give him a plot using the data analytics technique of his choice. He was interested in showing grouping patterns in his data using PCA plots.
When I got to know John was dealing with a data problem, I got curious. So I asked him, can I see the data? And he gladly shared the data with me, looking for a better outcome.
But it was in vain. Even I couldn’t create a PCA plot out of John’s data. The reason was that John was trying to make a PCA plot using a dataset that could be easily visualized without a dimensionality reduction method. In other words, it was data that could be easily visualized in a two-dimensional space without using any machine learning algorithm.
But then why was John after the PCA? After we talked for a few more minutes, John said that he saw this method in a research paper and believed it would solve his problem. This explanation helped me to identify the root cause. At the same time, it triggered me to write down this article. I am writing this article for all the Johns who need a helping hand in selecting the most appropriate analytics approach to solve your problem.
Data Analytics Method for 2-Dimensional Data
Try the simplest approach first. If it can be done in Excel, then do it in excel! Taking a lesson from John’s experience, always try to do the simplest step first. Ask yourself, ‘Can I plot this in Excel?’ If the answer is yes, just do it right away. You can either choose to just plot the data for exploratory analysis or build a simple linear regression model for quantitative modeling depending on the use case.
Data Analytics Method for Slightly Dimensional Data
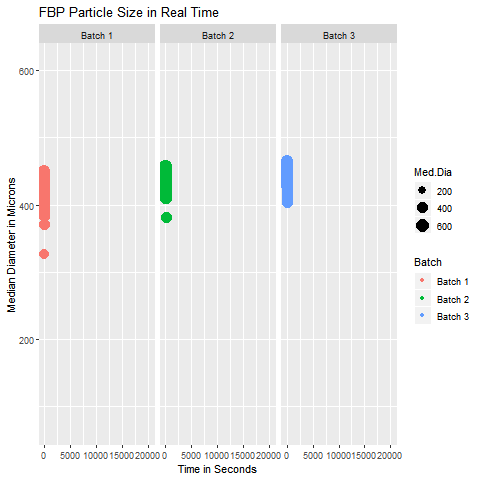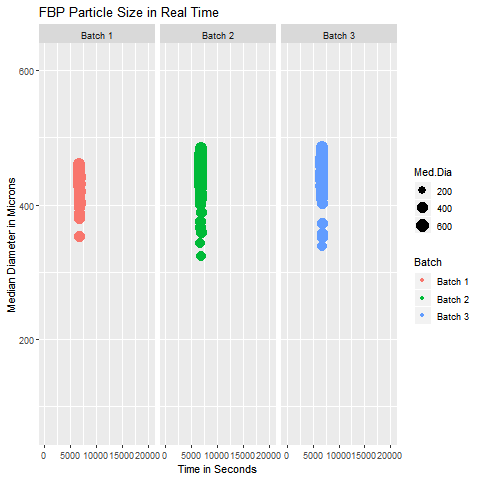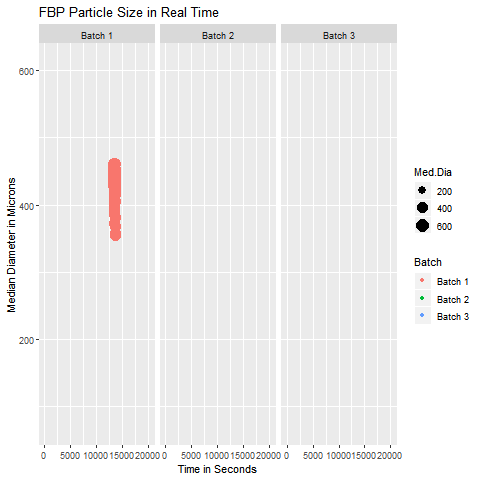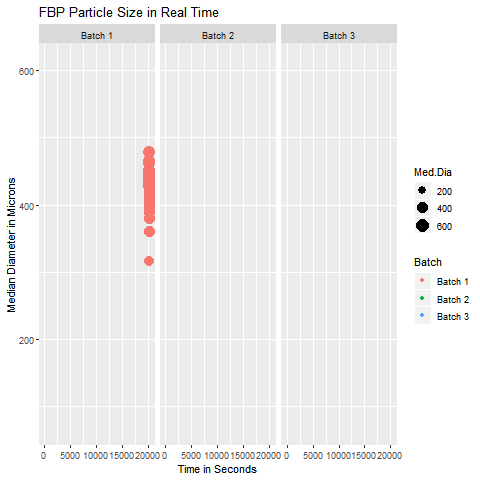
These are simple but tricky cases where the problem you are trying to solve may not need dimensionality reduction, but plotting the data wouldn’t be as simple as plotting an XY chart in Excel. In such cases, you can get help from data analysts who can suggest statistical software like Minitab and JMP to select the appropriate data analytics technique. In case you can’t access them, you can hire your data analyst friend to write a code for you to visualize that data. An example of such a exploratory data analytics method is shown below:
This graphic helps in visualizing the Particle Size Distribution of Material as it is getting processed in a similar manner for three different batches. It was a simple yet slightly tricky data with 4 columns (Median Diameter-Batch 1, Median Diameter-Batch 2, Median Diameter-Batch 3, and TimePoint)
Data Analytics Method for Highly Dimensional Data with Grouping Patterns
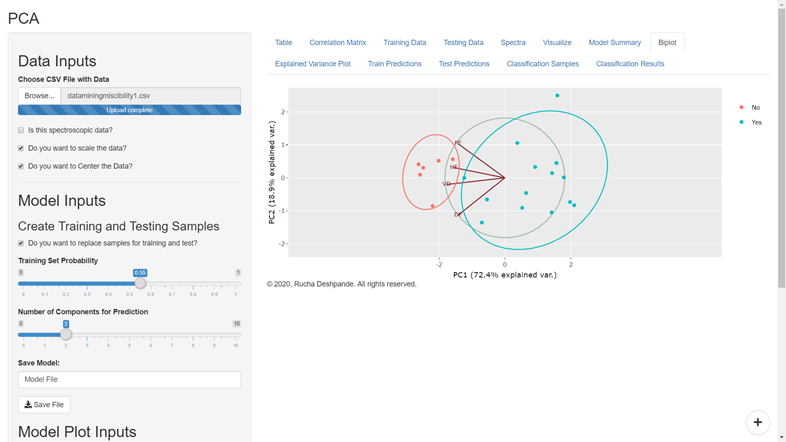
Suppose your data is highly dimensional with too many rows and columns that can not be plotted on an XY plot or even with the help of your data analyst friend, then you need a data analytics method for dimensionality reduction. For example methods like PCA or LDA can help you manage such data. However, the grouping pattern in the data can be visualized if you can assign a group to each observation in your data set. These methods don’t only give you an option of visualizing your data but also give you a chance to determine the group of an unknown sample.
It is a PCA plot that shows two groups in the data. The group labeled ‘Yes’ is miscible with the drug and the group labeled ‘No’ is immiscible with the drug. In the future, this model can predict if an unknown material is miscible with the drug or not.
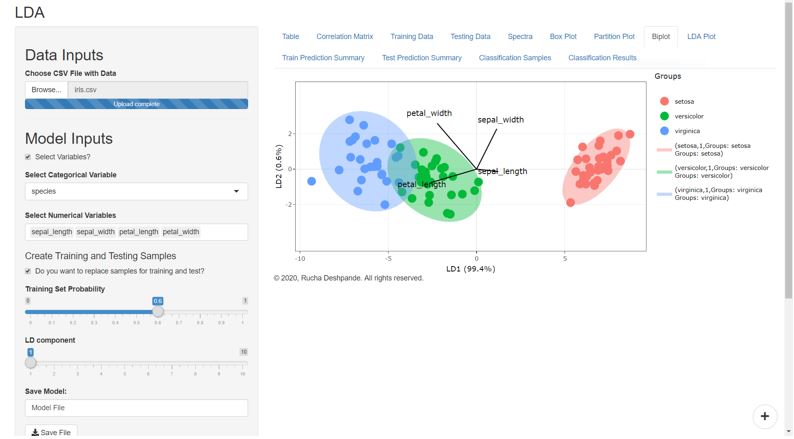
For example, suppose you used data from four mango species by assigning them to four different groups corresponding to their species. In that case, you can train a PCA or LDA model to predict the species of a mango sample whose species is not yet determined.
Similar to the Mango problem, here the LDA model predicts the species of an Iris flower.
However, it should be noted that LDA models do better when the variables are not highly correlated with each other. Whereas the PCA model works better with multilinear data.
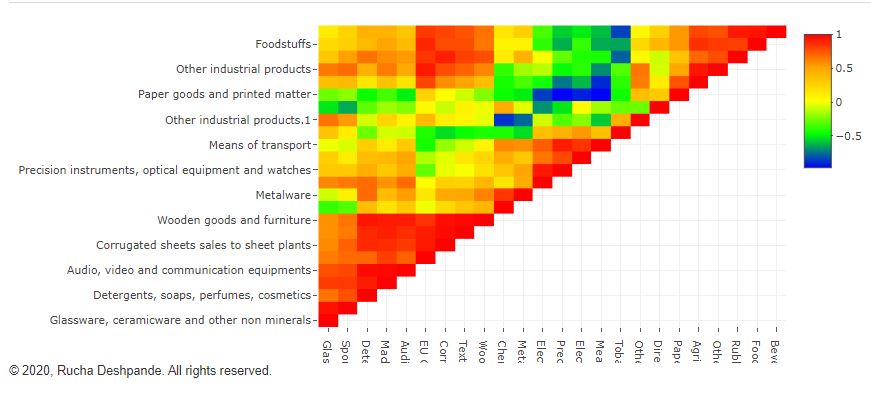
The multicollinearity or correlations between variables occurs when one variable increases or decreases with other variables. For example, if the height and weight of individuals are collected in the form of variables that describe an individual, then it is likely that an increase in height will result in an increase in weight. Therefore, we can say that the data has a multicollinearity problem in such a case.
The multicollinearity of variables can be judged on the basis of this heatmap. The higher the positive relationship between variables closer the color to the red, the higher the negative relationship between variables closer the color is to blue. If the color is closer to yellow then there is no collinearity issue.
Data Analytics Method for Highly Dimensional Data with Numerical Response
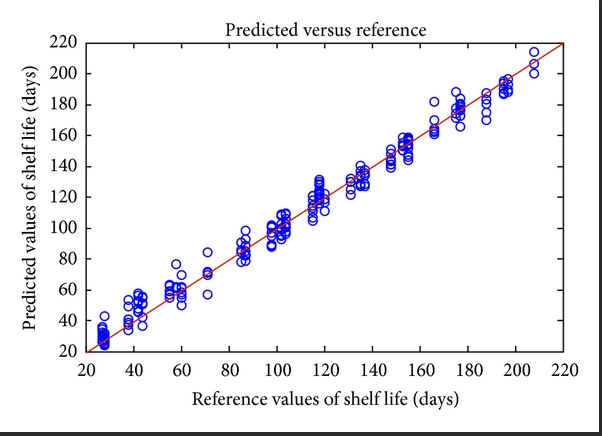
When highly dimensional data is being represented in the form of a number instead of a group, then quantitative data analytics techniques such as PCR, PLS, and MLR come to your rescue. Out of these, PCR and PLS work best on highly correlated data, whereas MLR works best for non-correlated data that follows normality assumptions. That is the reason PCR and PLS (and even PCA) techniques work well with sensor data from spectroscopes.
PCR, PLS, and MLR methods can predict the quantitative value of the response. The model performance is judged based on the closeness of the predicted value with the reference value in the known samples. If the predicted and reference values are aligned well as shown in the above picture then the model can be used for future predictions of unknown samples.
If you are using DataPandit’s smartMLR application, then you can even build a linear regression model using 2-dimensional data as it can handle small data (widthwise) as well as big data (widthwise).
All these quantitative data analytics methods help you predict future outcomes in numerical format. For example, if you have data of 10 different metals alloyed by mixing in varying proportions and the resultant tensile strength of the alloy. Then, you can build a model to predict the tensile strength of future alloy that can be made by changing the proportion of component alloys.
To Summarize
More data analytics techniques can be mentioned here, but I am mentioning the ones available for the DataPandit users. However, the key takeaway is that whenever you face a data analytics problem, then only start searching for a solution. Don’t be like John, who figured out the solution and then tried to fit his problem into the solution. My two cents would be to let the data analytics method work for you rather than you working for the data analytics method! Don’t stop here, share it with all the Johns who would like to know this!
As the name suggests, self-service analytics platforms are tools that help you do data analysis and modeling without coding knowledge. If you are planning to invest in such a platform you should give thorough consideration to the following 11 qualities to avoid future disappointments. It is important to do background research, since, the users are expected to help themselves with these platforms.
Why are Self Service Analytics Platforms Becoming Popular
People are coming up with awesome data products owing to the revolutionary developments in the Internet of Things, and data-based decision making. As a consequence, the competition in the domain is increased at an unprecedented rate. The data products lose their market value if they are not launched in time. There is a large chunk of data available in public domain. It can be utilized by anyone to make a data product. Hence, there is a sense of urgency in launching products like never before. Here the Self Service Analytics Platform comes into the picture as they not only cut down on hiring a dedicated engineer but also drastically reduce the turnaround time for modeling. This is the main reason why Self Service Analytics Platforms are gaining popularity.
Why Should You be Choosy about Analytics Platform Providers
As stated earlier, you need to help yourself with the platform. Therefore, you need to be a bit choosy about the provider to make the right choice to avoid any regrets later. The following 11 qualities will guide you to choose the right provider.
Top 11 Qualities of Self Service Analytics Platform Providers
# 1: They Understand Your Business
A right service provider has a sound understanding of the ‘ask’ that you have. As a beginner you will only have an imaginary picture of what your product is going to be like. You need to communicate your thoughts to the platform provider effectively. When you and the platform provider understand each other’s language then exchange of these ideas becomes a breeze. It is possible only of the platform provider understands your business.
#2: They don’t consume the entire space on your harddisk
There are some Self Service Data Analytics Platforms that can easily consume 100s of GBs of space on your computer. You definitely don’t want to lose out on the speed of your system just to avoid the coding. An ideal platform provider is the one who not only saves on your coding effort but also helps you to be more efficient and agile. A cloud based platform overcomes the requirement of huge storage space very easily.
#3: They have quick calculation time
If you spend millions on a analytics platform provider that takes 2-3 days to make its calculation then it is obviously not going to serve your purpose. Hence go for an analytics platform that gives out quick results.
#4: They don’t sell what you don’t need
We all have been in situation when we reach out to a service provider to buy XX but the service provider insists on buying a package that contains XX as one of the features. In the end, you get what you want but you also end up spending more. Things are even worst, if you also don’t know how to make the best use of the additional features you paid for. Underutilization of the resources is also a waste. Therefore, it is wise to choose a service provider who can sell you only what you need.
#5: They have a user-friendly interface
User-friendly interface is a must have for a ‘Self Service Analytics Platform’ as you need to serve yourself. An interface that can be customized as per your need is an added advantage. Hence while choosing your platform ensure that the navigation across the platform is intuitive.
#6: They are ready to answer your service request
These days users are applying data analytics to versatile problems. All problems have different data-pretreatment needs and visualization needs. In such a scenario, you need to look for a data analytics platform provider who pays heed to service request. Rigid providers who follow ‘one size fits all’ approach may not be fit for you in such an instance.
#7: They provide a platform that offers more functionalities than Excel or Google Worksheet
If your project is just about creating dashboard to visualize line plots, histograms and box plots. You are better off doing that work with excel or google worksheet. Why spend on something that your organization already has?
#8: They don’t charge you a bomb for maintenance of the Analytics Platform
Some analytics platform providers can quote you an astonishingly convincing price, only for you to realize several hidden costs later. To avoid this problem it is best to get things clear in your first meeting. A reasonable maintenance should be one of the deciding criteria for the provider.
#9: They don’t provide a database management solution in the name of Analytics Platform
Although database management solutions play an important role before beginning the data analysis, they may not be a necessity for you especially if you don’t plan to extract data from a specified resource. It is always good to have clarity if your problem is a data engineering problem or a data analytics problem.
#10: They provide onboarding training on their analytics platform
The sustainability of new technology adoption invariably depends on the effectiveness of onboarding training. Hence a provider who is ready support you for the onboarding training should be your first choice.
#11: They are not just data analytics platform providers but your data analytics partners
Yes, it is a self-help platform, but that doesn’t mean the platform provider gives you the cold shoulder when discussing your challenges. A flexible data analytics platform provider ready to partner with you to overcome the challenges and help you win the race should be a priority.
Conclusion
Choosing the right Self Service Analytics Platform provider is one big project in itself. The platform efficiency and flexibility of the platform service provider are game-changer for any data product. At Let’s Excel Analytics Solutions LLP, we work really hard to fulfill our clients’ ask on all the 11 qualities mentioned above.
Ever wondered why Clive Humby famously coined the 'Data is new oil' phrase? Well, this blog article tells you exactly what he meant. The latest advancements in data analytics, cloud infrastructure, and increased emphasis on making data-driven decisions have opened up several avenues for developing Data Science Products. People can build amazing data-based products that can generate revenues. In other words, the data is the new money-making machine. In this article, we will discuss the top 3 things that you must know about data science products.
# 1: What is a Data Science Product?
Data Science Product is a new era money-making machine that is fueled by data and built using machine learning techniques. It takes data as input and gives out valuable business insights as an output.
#2: Examples of Data-based Products
Classic examples of data products include Google search and Amazon product recommendations, both these products improve as more users engage. But the opportunity for building data-based products extends far beyond the tech giants. These days companies of all range of sizes and across almost all sectors are investing in their own data-powered products. Some inspirational examples of data science products that are developed by non-tech giants are as below:
HealthWorks
It mimics consumer choice in Medicare Advantage. The product compares and contrasts more than 5000+ variables across plan costs, plan benefits, market factors, regulatory changes, and many more. It helps Health Plans identify the top attributes that lead to plan competitiveness, predict enrolments, design better products and create winning plans.
Cognitive Claims Assistant
Damage assessment in vehicles is an important step for insurance claims and auto finance industry. Currently, these processes involve manual interventions requiring a long turnaround time. Cognitive Claims Assistant (CCA) by Genpact automates this process. The data product not only reduces cost and time in the process but also accurately estimates the cost of repairs.
#3: How to Build Data Powered Products?
Do you want to build a data science product too? Here are the five steps that will help you to build a good data science product:
Step 1: Ideation and Design of Data Product
Ideation
The first step of building a data science product is Conceptualizing the product. Conceptualization starts with identifying potential opportunities. A good data science product is the one that solves a critical business need. An unsolved business need that can be solved using data is an opportunity for building data products.
Design
Design the data structure that you will need to solve the business need. This often involves brainstorming on various data inputs and their corresponding valuable outputs that will solve the business need.
Step 2: Get the Raw Data
The second step in building data products is getting the data. If you already own the data, you are already covered for this. All you have to do is move on to the next step. If you don’t have the data then you need to generate or gather it.
Step 3: Refine the Data
As they rightly say, data is the new oil but it is of no use until it is refined like an oil. Understand the structure of your data. Refine, clean, and pre-process it if it is unstructured. Always remember the golden rule-‘Garbage in is Garbage out!’ Knowing the data helps you clearly define the inputs and outputs from your data science product.
Step 4: Data Based Product Development
This is the most tricky part in data science product development and needs a strong knowledge of the business process, business needs, statistics, mathematics, and coding. This knowledge forms the backbone of the data product. In the majority of the cases, this step involves building a machine learning model using domain knowledge. In some cases, it could also involve simple graphical outputs for exploratory analysis of the data. No matter what is the output the codes developed for executing the desired process need to be tested and validated for real-life use of the data product.
Step 5: Release!
This is the last step in data product development. In this step, tried, tested, and validated data science product is deployed on a cloud. The data product buyers can simply log in from anywhere in the world and use the product.
Conclusion
Anybody who owns the treasure trove of the data should develop a ‘Data Science Product’ or a ‘Data Product’. Now the question arises, is it possible to build data products without coding knowledge? And the answer is, absolutely yes! You can use our data analytics platforms that are specially built for non-coders. All you have to do is arrange your data meaningfully and just make few clicks to build your base model described in Step 4 of How to build data products as described above. When you deploy the model on the cloud your money-making machine becomes a reality. If you don’t like the idea of doing it all yourself, then you always have an option to outsource.
Like any other product, the success of the data product is dependent on its usability. Half the battle is won with a strong business case. The remaining battle can be won with mathematics, statistics, and computer science. This is exactly where we can contribute. Our aim to accelerate the data product development process. Let's unite your domain knowledge and data with our data modeling capabilities. Let's build amazing data science products!