
Data visualization is the first step in data analysis. DataPandit allows you to visualize boxplots as soon as you segregate categorical data from numerical data. However, the box plot does not appear until you uncheck ‘Is this spectroscopic data?’ option in the sidebar layout, as shown in Figure 1.

The box plot is also known as ‘Box – Whisker Plot’. It provides 5-point information, including the minimum score, first (lower) quartile, median, third (upper) quartile, and maximum score.
When Should You Avoid Boxplot for Data Visualization?
The box plot itself provides 5-point information for data visualization. Hence, you should never use a box plot to visualize data with less than five observations. In fact, I would recommend using a boxplot only if you have more than ten observations.
Why Do You Need Data Visualization?
If you want a DataPandit user, you might just ask, ‘Why should I visualize my data in first place? Wouldn’t it be enough if I just analyze my model by segregating the response variable/categorical variable in the data?’ The answer is, ‘No’ as data visualization is the first step before proceeding to data modeling. Box plots often help you determine the distribution of your data.
Why is Distribution Important for Data Visualization?
If your data is not normally distributed, you most likely might induce bias in your model. Additionally, your data may also have some outliers that you might need to remove before proceeding to advanced data analytics approaches. Also, depending on the data distribution, you might want to apply some data pre-treatments to build better models.
Now the question is how data visualization can help to detect these abnormalities in the data? Don’t worry, we will help you here. Following are the key aspects that you must evaluate while data visualization.
Know the spread of the data by using a boxplot for data visualization
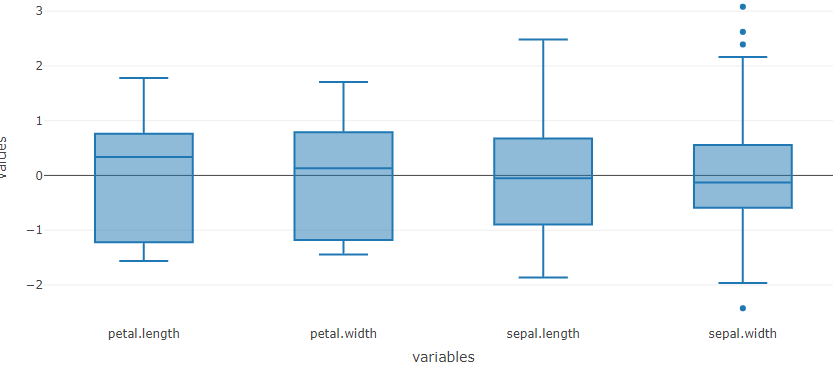
Data visualization can help you determine the spread of the data by looking at the lowest and highest measurement for a particular variable. In statistics, the spread of the data is also known as the range of the data. For example, in the following box plot, the spread of the variable ‘petal.length’ is from 1 to 6.9 units.

Know Mean and Median by using a boxplot for data visualization
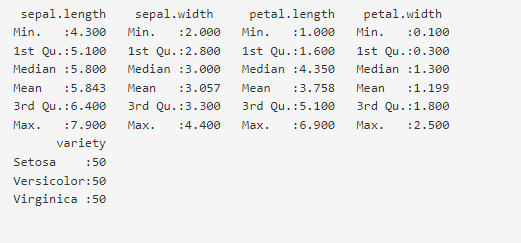
Data visualization with boxplot can help you quickly know the mean and median of the data. The mean and median of normally distributed data coincide with each other. For example, we can see that the median petal.length is 4.35 units based on the boxplot. However, if you take a look at the data summary for the raw data, then the mean for petal length is 3.75 units as shown in Figure 3. In other words, the mean and median do not coincide which means the data is not normally distributed.
Know if your data is Left Skewed or Right Skewed by using boxplot for data visualization
Data visualization can also help you to know if your data is skewed using the values for mean and median. If the mean is greater than the median, the data is skewed towards the right. Whereas if the mean is smaller than the median, the data is skewed towards the left.
Alternatively, you can also observe the interquartile distances visually to see where most of your data lie. If the quartiles are uniformly divided, you most likely have normal data.
Understanding the skewness can help you know if the model will have a bias on the lower side or higher side. You can include more samples to achieve normal distribution depending on the skewness.
Know if the data point is an outlier by using a boxplot for data visualization
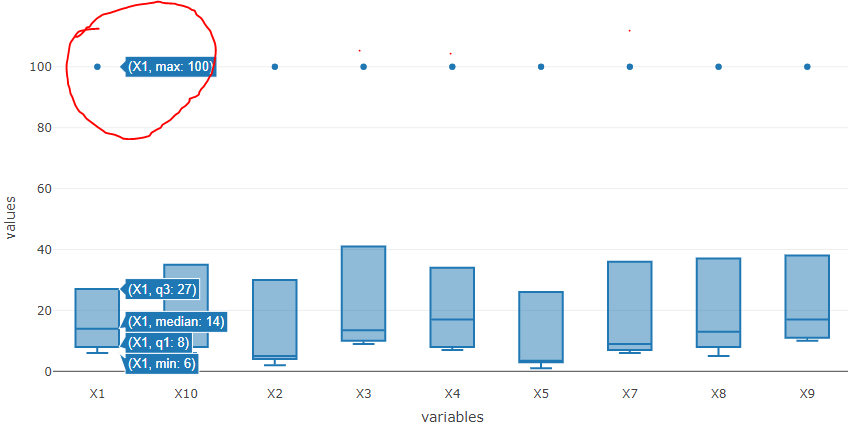
Data visualization can help identify outliers. You can identify outliers by looking at the values far away from the plot. For example, the highlighted value (X1, max=100) in Figure 4 could be an outlier. However, in my opinion, you should never label an observation as an outlier unless you have a strong scientific or practical reason to do so.
Know if you need any data pre-treatments by using boxplot for data visualization
Data visualization can help you know if your data needs If the data spread is too different for different variables, or if you see outliers with no scientific or practical reasons, then you might need some data pre-treatments. For example, you can mean center and scale the data as shown in Figure 5 and Figure 6 before proceeding to the model analysis. You can see these dynamic changes in the boxplot only in the MagicPCA application.

x
Conclusion
Data visualization is crucial to building robust and unbiased models. Boxplots are one of the easiest and most informative ways of visualizing the data in DataPandit. Boxplots can be a very useful tool for spotting outliers, and understanding the skewness in the data. Additionally, they can also help to finalize the data pre-treatments for building robust models.
Need multivariate data analysis software? Apply here to obtain free access to our analytics solutions for research and training purposes!