Computational Techniques are quick, easy, reliable, and efficient methods for solving mathematical, scientific, engineering, geometrical, geographical, and statistical problems. These techniques invariably utilize computers, and hence the name. They are specifically, steps or algorithm-based execution for achieving a solution to the problems. In other words, computational Techniques deliver solutions using mathematical models and Computational Tools.
Suitability of Computational Techniques in Medicine
Computational intelligence tools and techniques can add great value to the Medical and Biomedical industry. In a sense, computational intelligence could be considered a complementary toolbox to standard Operational Research (OR) methods and techniques for optimization, problem-solving, and decision-making.
As a result, the computational have become the method of choice for problems and areas having specific characteristics, as mentioned below:
High degree of complexity,
Linguistic representation of concepts or decision variables,
High degree of uncertainty, Lack of precise or complete data sets, etc.
Applications:
The following paragraphs discuss applications computational techniques in Medical and Biomedical industry.
Computational Medicine
Computational Medicine aims to advance healthcare by developing computational models of disease, personalizing these models. This Personalization is achieved using data from patients, and applying these models to improve the diagnosis and treatment of disease. The personalized patient models can discover:
Novel risk biomarkers,
Predict disease progression,
Designs optimal treatment,
Identify new drug targets for treating cancer, cardiovascular disease, and neurological disorders.
Computational Techniques in Drug Discovery
Computer-Aided Drug Design (CADD) Technique significantly decreases the number of compounds necessary to screen. Interestingly CADD achieves this while retaining the same level of lead compound discovery. Many compounds that are predicted to be inactive can be skipped, and those predicted to be active can be prioritized. Thereby reducing the cost and workload of a full high-throughput screening (HTS) without compromising lead discovery. Additionally, traditional HTS assays often require extensive development and validation before they can be used. CADD requires significantly less preparation time. Hence the experimenters can perform CADD studies while thetraditional HTS assay is being prepared.
Finally, the fact that both of these tools can be used in parallel provides an additional benefit for CADD in a drug discovery project. It is capable of increasing the hit rate of novel drug compounds because it uses a much more targeted search than traditional HTS and combinatorial chemistry. It not only aims to explain the molecular basis of therapeutic activity but also to predict possible derivatives that would improve activity.
Nuclear Medicine and Radiotherapy
Modeling and simulation in radiation-related practices are becoming more and more popular. As a result, various algorithms, codes, and software have been developed for the same. For example, researchers are using the Monte Carlo method, role model the interaction of photons, electrons, positrons, and neutrons with the environment. Interestingly the approach provides most accurate representation of dose distributions in the patient and phantom calculations.
Furthermore, the techniques are extend their applications in nuclear medicine.
Therapeutic Decision-Making
The current paradigm for surgery planning for the treatment of cardiovascular disease relies exclusively on diagnostic imaging data. Firstly, the data defines the present state of the patient. Secondly, the Empirical data can be helpful to evaluate the efficacy of prior treatments for similar patients and to judge a preferred treatment. Owing to the individual variability and inherent complexity of human biological systems imaging and empirical data alone are insufficient to predict the outcome of a given treatment for an individual patient. As a result, the physician utilizes computational tools to construct and evaluate a combined anatomic/physiologic model to predict the outcome of alternative treatment plans for an individual patient.
The predictive medicine paradigm is implemented in a software system developed for Simulation-Based Medical Planning. This system provides an integrated set of tools to test hypotheses regarding the effect of alternate treatment plans on blood flow in the cardiovascular system of an individual patient. It combines an internet-based user interface developed using Java and VRML, image segmentation, geometric solid modeling, automatic finite element mesh generation, computational fluid dynamics, and scientific visualization techniques. And thus devise a proper plan for the treatment of the patient.
Prediction, Prevention, Diagnosis, and Treatment of Neurodegenerative Diseases
Neurodegenerative disorders, such as Alzheimer’s disease (AD), Parkinson’s disease (PD), and Amyotrophic lateral sclerosis (ALS), are formidable clinical illnesses whose diagnosis, treatment, and prognosis are complex. As a result, no effective treatment for AD has been found so far. With the assistance of biomarkers identified by computational methods, neurologists can diagnose the disease at its early stage.
Similarly, based on next-generation sequencing (NGS) technologies, the risk gene loci and proteins can be detected with the help of computational technologies.
When these techniques are accompanied by Magnetic Resonance Imaging (MRI) technology, clinicians can improve or assure their diagnosis and classification of neurodegenerative disorders.
All in all, appropriate bioinformatics tools can help biologists to explore the etiology of neurodegenerative diseases. The etiology may shed light on the underlying mechanisms of brain impairment. In addition, some biomarkers can promote drug repurposing as well as de novo drug design.
Conclusion
Computational Methods have been continuously progressing in all fields and especially in the Field of Medicine. Right from the development of new techniques for developing and designing medicine for various treatments. To advancements in therapies like laser surgery, and robot hands for surgeries. To making clinical and treatment decisions using the data and computational methods.
In conclusion, Computational Methods have become an integrated part of many fields and especially Medicines. And we foresee more development to come along the way of Computational Methods in Medicine.
Introduction to Predictive Analytics in Health Care
Predictive analytics in Healthcare has had a huge impact on the healthcare system and finds a great many applications driving innovations related to patient care. The purpose of this blog is to apprise you of the wonders predictive analytics is doing in the patient-care.
“Predictive analytics is a branch of Data Science that deals with the prediction of future outcomes. However, it is based on the analysis of past events to predict the future outcomes.”
Talking about predictions has always fascinated mankind since time immemorial. Nostradamus set forth prophecies about catastrophes, disease, health, and well-being. Who would have known that this art of foretelling could transform into a Science, PredictiveAnalytics!
Advantages of the applications of predictive analytics in healthcare.
Predict curable diseases at the right time.
Predict pandemic and epidemic outbreaks.
Mitigate the risks of clinical decision making.
Reduce the cost of medical treatments.
Improve the quality of patient life.
“Patient-care has quite a transitioned from relying on the extraordinary ability of a physician to diagnose and treat diseases to the use of sophisticated and state-of-the-art technology to provide innovative patient care”
For the matter of discussion, the applications of predictive analytics in healthcare have been divided into three aspects of patient care.
Diagnosis
Prognosis
Treatment
Use of predictive analytics in medical diagnosis
Early detection of cancer
Many Machine Learning algorithms are being used by clinicians for the screening and early detection of precancerous lesions. QuantX (Qlarity Imaging) is the first USFDA approved ML breast cancer diagnosis system for predictive analytics. This computer-aided (CAD) diagnosis software system assists radiologists in the assessment and characterization of potential breast anomalies using Magnetic Resonance Imaging (MRI) data. Another image processing ML application is developed by the National Cancer Institute (NCI) that uses digital images taken of women’s cervix to identify potentially cancerous changes that require immediate medical attention.
Predisposition to certain diseases
Predictive analytics has a huge potential to determine the occurrence and predisposition of genetic and other diseases. This domain leverages the data collected from the human genome project to study the effect of genes linked to certain disorders. This is known as pleiotropic gene information. Many such models have been developed to determine the risk of manifesting diseases like osteoporosis, diabetes, hypertension, etc., in the later stages of life.
Prediction of disease outbreaks
The prediction of disease outbreaks that could eventually turn epidemic and pandemic is an indispensable tool for emergency preparedness and disaster management. Many lives could be saved if the outbreak of such diseases is known to us in the first place. However, the efforts of researchers modeling the spread of deadly diseases like Covid19, Zika, and Ebola viruses have yet to bear the fruit of success. The most probable reason could be the complexities in the data collection procedures and the highly dynamic nature of the pathogens like viruses.
Use of predictive analytics in disease prognosis.
Deterioration of patients in ICU
The predictive algorithms developed from continuous monitoring of the vital signs of a patient are used to predict the probability of the patient deterioration and need for immediate intervention in the next 1 hour or so. It is well established that early intervention has a huge success in preventing patient deaths. These predictive algorithms are also used in the remote monitoring of patients in intensive care units (ICU). The remote monitoring of patients, also known as Tele-ICU, is highly effective for aiding intensivists and nurses during situations like Covid19 when the healthcare system is pushed to the limit.
Reducing hospital stays
Prolonged hospital stay and readmission rates are very expensive in the patient’s pockets. The analysts are constantly looking at the patient data to monitor the patient prognosis to treatment that averts any unwarranted hospital stay. The effect of the future outcomes on patient health can also be determined to customize the patient-specific treatment modalities that prevent readmissions.
Risk scoring for chronic diseases
Predictive analytical applications have been designed that can identify patients who are at high risk of developing chronic conditions in the early stage of disease progression. The early detection of the disease progression allows better management of the condition. In the majority of the cases, the disease prognosis could be controlled to a great extent to have a significant effect on the patient’s quality of life.
Predictive analytics in treatment of diseases
Virtual hospital settings
Philips developed a concept technology of virtual hospital settings for predictive care of high-risk patients at their homes. This analytics employs data from the medical records of thousands of patients and the medical history of a particular patient (senior) to build predictive models that can identify the patients who are at risk of emergency treatment in the next month. Various devices have been developed that provide alerts for potential emergency treatment and are known as Automatic Fall Detection (AFD). The AFD collects data continuously from the patient’s movements in all directions (using accelerometer sensors) and uses the data to pick the subtle differences between normal gait and potential fall situations. This device has gained so much popularity that Apple added this feature to Apple Watch Series 4.
Digital twins
Another marvel of predictive analytics for patient care is digital twin technology. In this technology, predictive analytics, IoT, and cloud computing tools are used to develop a virtual representation of the human body. The virtual representation mimics the actual biochemical processes in the human body by constantly collecting data from millions of such patients. The data is modeled to project the possible cause of the patient’s symptoms and suggest the most viable treatment modality specific to the patient’s condition. The treatment modality recommended by the twin can be assessed virtually before implementation on the patient and possible complications can be known and averted in the first place.
Conclusion
The adoption of predictive analytics has ushered personalizedand patient-centric transformations into the healthcare industry. However, its scope is not limited to patients alone, it has a huge potential to overhaul other areas of the healthcare system like administration, supply chain, engineering, public relations, and so on.
Interested in building predictive analytical capabilities in your organization?
Technology has been evolving very expeditiously over the past decade. These advancements have set off a trend for learning with technology. To satisfy the learning needs, people are embracing self-directed learning. It is important to mention that as the world is preparing for the Fourth Industrial Revolution (I4.0), the workforce has to keep up with the advancements in technology. At the same time, there has been quite a buzz around the Machine Learning and Artificial Intelligence that forms the heart and soul of the I4.0. In other words, learning Machine Learning is the need of the hour.
Now that it is imperative to learn Machine Learning, there are three success mantras of mastering it: PRACTICE, PRACTICE, and PRACTICE. But the basic question that comes up in our mind is, what to practice on. A true dataset should be available to work on as if dealing with a real ML problem. In this blog, we will be discussing some of the most popular data repositories for extracting sample datasets for mastering Machine Learning skills.
Data, DataSet, and Databases
Before we begin, it’s important to clear the air by defining the basic definitions related to datasets.
What is data?
Data is a collection of information that is based on certain facts.
What is a dataset?
Dataset is a structured collection of data.
What is a database?
The database is an organized collection of multiple datasets.
The data which is used can be collected from various sources such as experimentations, surveys, polls, interviews, human observations, etc. It can also be generated by machines and directly archived into databases.
DataSets For Machine Learning Projects
The choice of data collection is a very crucial step in the success of the Machine Learning program. The source of the datasets is equally important, as it is a matter of the reliability and trueness of the collected data. Some of the most popular data repositories that are required for acquiring Machine Learning datasets are discussed below.
KAGGLE
This platform is owned by Google LLC and is a repository of huge data sets and code that is published by its users, the Kaggle community. Kaggle also allows its users to build models with the Kaggle datasets. The users can also discuss the problems faced in analyzing the data with its user community.
Kaggle also provides a platform for various open-source data Science courses and programs. It is a comprehensive online community of Data Science professionals where you can find solutions to all your data analytics problems.
UCI MACHINE LEARNING REPOSITORY
UCI Machine Learning repository is an open-source repository of Machine Learning databases, domain theories, and data generators. This repository was developed by a graduate student, David Aha, at the University of California, Irvine (UCI) around 1987. Since then, the Centre for Machine Learning and Intelligent Systems at the UCI is overseeing the archival of the repository. It has been widely used for empirical and methodological research of Machine Learning algorithms.
QUANDL
Quandl is a closed-source repository for financial, economic, and alternative datasets used by analysts worldwide to influence their financial decisions. It is used by the world’s topmost hedge fund, asset managers, and investment banks.
Due to its premiere and closed-source nature, it cannot be used for just practicing Machine Learning algorithms. But citing its specialization in financial datasets, it is very important to include Quandl in this list. Quandl is owned by NASDAQ, American Stocks Exchange based in New York City.
WHO
World Health Organisation (WHO) is a specialized agency of the United Nations Organisation headquartered in Geneva, Switzerland. It is responsible for monitoring international health and continually collects data related to health across the world. WHO has named its repository of data as Global Health Observatory (GHO). The GHO data repository collects and archives health-related statistical data of its 194 member countries.
If you are looking for developing Machine Learning algorithms on health-related problems, GHO is one of the best sources of data collection. It is a repository of a wide variety of information ranging from a particular disease, epidemics, and pandemics, world health programs, and policies.
GOOGLE DATASET SEARCH
Google dataset search is a search engine for datasets powered by Google. It uses a simple keyword search to acquire datasets hosted in the different repositories across the web. It hosts around 25 million publicly available datasets to its users. Most data in this repository is government data besides a wide variety of other datasets.
AMAZON WEB SERVICES (AWS)
Amazon Web Services is known as the world’s largest cloud services provider. AWS has a registry of datasets that can be used to search and host a wide variety of resources for Machine Learning. This repository is cloud-based, allowing users to add and retrieve all forms of data irrespective of the scale. AWS also enables data visualization, data processing, and real-time analytics to make well-informed decisions driven by data.
Conclusion
The human resources are prepping up for Workforce 4.0 by constantly acquiring new skills. Machine Learning is one of the most indispensable skills for tomorrow’s workforce. In today’s world of the digital revolution, information is available at our fingertips. The datasets for Machine Learning are also available as open-source and could be utilized to build algorithms for making informed decisions.
GLOBOCON 2020, one of the key cancer surveillance projects of the International Agency for Research on Cancer (IARC), published recent statistics of global cancer epidemiology. According to this report, 19,292,789 new cancer cases were reported in 2020 i.e., a two-fold increase in the number of cases as reported in 2018. For over 19 million cases of cancer reported, 9,958,133 cancer-related deaths were reported in the same year. As per the estimates of the International Agency for Research on Cancer (IARC), every 1 person in 5 persons is likely to develop cancer during their lifetime. In this article we are going to discuss how Predictive Analytics can play a major role in changing Cancer Statistics.
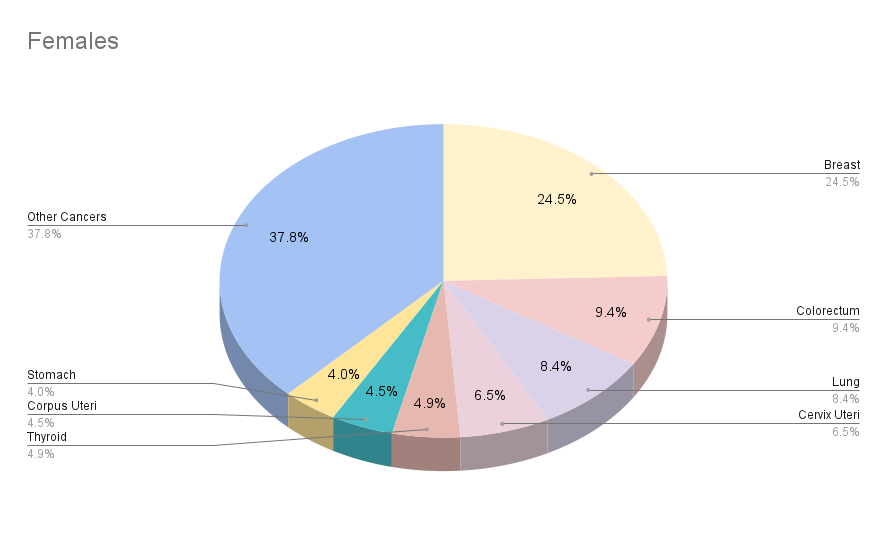
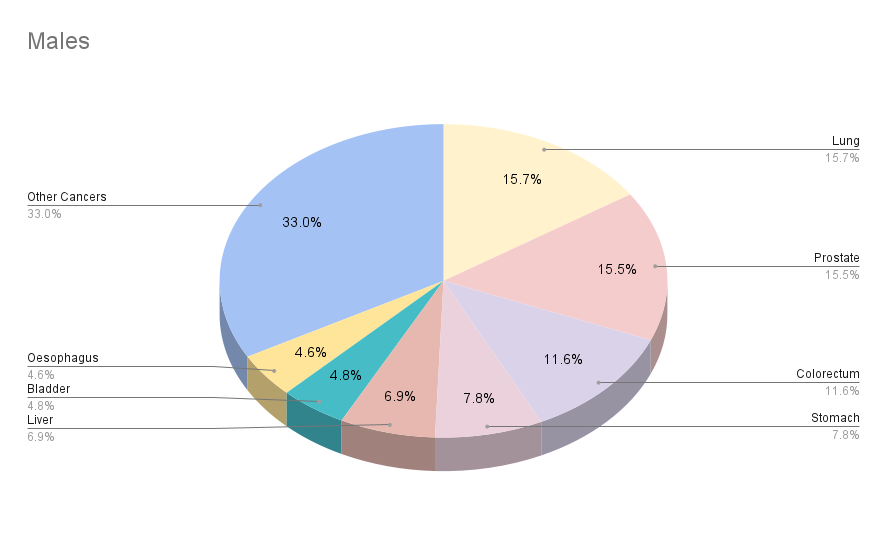
Cancer Statistics: 2020
Males
Females
Population
3,929,973,836
3,864,824,712
Number of new cancer cases
10,065,305
9,227,484
Number of cancer deaths
5,528,810
4,429,323
5 year prevalent cases
24,828,480
4,429,323
Top 5 most cancers excluding non-melanoma skin cancer
These alarming and constantly rising figures have refocused the attention of medical scientists on the early screening and diagnosis of cancers using Predictive Analytics. Because cancer mortality and morbidity can be reduced by early detection and treatment of cancer.
American Cancer Society (ACS) issues updated guidelines and guidances related to an early screening of cancers to assist in making well informed decisions about the tests for early detection of some of the most prevalent cancers (breast cancer, colon and rectal cancer, cervical cancer, endometrial cancer, lung cancer, and prostate cancer). The early detection of precancerous lesions and cancers is broadly divided into three categories:
Early cancer diagnosis
Cancers respond very well to the treatment only if diagnosed early that, in turn, increases the chances of cancer survival. As per WHO guidance, early diagnosis is a three-step process that must be integrated and provided in a timely manner.
Awareness of cancers and accessing care as early as possible
Clinical evaluation of cancers, appropriate diagnosis and staging of cancers
Access to the right treatment at the right stage.
Screening of cancers
Screening identifies specific markers of cancers that are suggestive of particular cancer. For example, visual inspection with Acetic Acid (VIA) test can be used for early screening of cervical cancers in women. Cervical lesions turn white for a few minutes after application of acetic acid.
However, the early diagnosis and screenings of cancer suffer from drawbacks like false positives, false negatives, and overdiagnosis which may lead to more invasive tests and procedures.To overcome this problem, scientists are using the power of Predictive Analytics based on Artificial Intelligence and Machine Learning.
Introduction to Artificial Intelligence (AI)
Artificial Intelligence (AI) is a great tool for Predictive Analytics and it is defined, in Webster’s dictionary, as a branch of computer science dealing with the simulation of intelligent behaviour in computers. In other words, it is the capability of machine to imitate intelligent human behaviour.
One of the early pioneers of Artificial Intelligence, Alan Turings, published an article in 1950 entitled “Computing Machinery and Intelligence.” It introduced the so-called, Turing test, to determine if a computer can exhibit the same level of intelligence as demonstrated by humans. The term “Artificial Intelligence” was coined by John McCarthy at the Artificial Intelligence (AI) conference at Dartmouth College in 1956. It was Allen Newell, J.C. Shaw, and Herbert Simon who introduced the first AI-based software program namely, The logic Theorist.
Majority of Artificial Intelligence (AI) applications use Machine Learning (ML) algorithms to find patterns in the datasets. These patterns are used to predict the future outcomes.
The basic framework of Artificial Intelligence (AI) consists of three main steps:
Collecting input data
Deciphering the relationship between input data
Identifying unique features of sample data
Introduction to Machine Learning (ML)
Machine learning (ML) is also another tool for Predictive Analytics and is defined in Webster’s dictionary as the process by which a computer is able to improve its own performance by continuously incorporating new data into an existing statistical model. It allows the system to reprogram itself as more data is added and eventually increasing the accuracy of the task assigned.
In the case of Machine learning (ML), it’s an iterative process so that the predictability of the system is improved each time. Most Machine Learning (ML) algorithms are mathematical equations in which sample data is plotted to observed variables, termed as features, and the outcomes termed as labels. The labels and features are used for the classification of different ML tools and techniques. Based on the label type, Machine Learning (ML) algorithms can be categorised into:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
In supervised learning, models are trained based on labelled datasets. For the purpose of prediction, the model needs to map the input variables with the output variables using a know mathematical function. Supervised learning can be used for understanding, Classification and Regression problems.
In unsupervised learning, data patterns are found in the un-labelled data and the endpoint of the unsupervised learning is to find characteristics patterns in the data. Unsupervised learning is used for identifying Clustering and Association in datasets.
Reinforcement learning is the ‘learning’ by interacting with the environment. A reinforcement learning algorithm makes decisions based on its past experiences and also by making new explorations.
The PCA part of MagicPCA 1.0.0. is an unsupervised Machine Learning Approach, whereas the SIMCA part of it is a Supervised Classification Technique.
Rising Interest in Biomedical Research
In the initial years, the journey of AI was not so easy, as can be seen in the period of 1974-1980, which is known as AI winter. During this period the field experienced its low in terms of researcher’s interests and government funding. Today, after decades of advances in data management and superfast computers, and renewed interests of government and corporate bodies, it is a practical reality and finds its applications in a wide variety of fields like e-commerce, medical sciences, cybersecurity, agriculture, space science, automobile industry, etc.
As the phrase “Data Science is everywhere” picked up, biomedical researchers started delving into Artificial Intelligence (AI) and Machine Learning (ML) to look for a better solution through Predictive Analytics. One inspiring story of Regina Barzilay, a renowned professor of Artificial Intelligence (AI) and a breast cancer survivor, portrays how her diagnosis of breast cancer reshaped her research interests. She hypothesized that AI and ML tools can extract more clinical information that helps clinicians make knowledgeable decisions. She collected data from medical reports and developed Machine Learning algorithms to interpret the radio diagnostic images for clinicians. One of the models developed by her has also been implemented in clinical practice that helps radiologists to read diagnostic images very well.
Current scenario: Predictive Analytics in Cancer Diagnosis
The concept of AI/ML has long been employed as Predictive Analytics tool in the radiodiagnosis of precancerous lesions and tumours.
The AI system reads the images generated by various radiological techniques like MRI, PET scan, etc., and processes the information contained in them to assist clinicians make conscious decisions on the diagnosis and progression of the cancers.
Breast Cancer Diagnosis with QuantX
The FDA’s Center for Devices and Radiological Health (CDRH) has approved the first AI-based breast cancer diagnosis system for Predictive Analytics. QuantX was developed by Qlarity Imaging (Paragon Biosciences LLC). QuantX is described as a computer-aided (CAD) diagnosis software system that assists radiologists in the assessment and characterization of breast anomalies using Magnetic Resonance Imaging (MRI) data. The software automatically registers images and segmentations (T1, T2, FLAIR, etc.), and analyses user-directed regions of interest (ROI). QuantX extracts this data from the ROI to provide computer-aided analytics based on morphological and contrast enhancement characteristics. These imaging analytics are then used by an artificial intelligence algorithm to get a single value, known as QI score, which is analysed relative to the reference database. The QI score is based on the machine learning algorithm that is generated from a training subset of features calculated on segmented lesions.
Cervical Cancer Diagnosis with CAD
National Cancer Institute (NCI) has also developed a computer aided program (CAD) that analyses digital images taken of women’s cervix and identify potentially precancerous changes that require immediate medical attention. This Artificial Intelligence-based approach is called Automated Visual Evaluation (AVE). A large set of data, around 60000 cervical images, was generated using the precancerous and cancerous lesions to develop a machine learning algorithm. This algorithm recognizes patterns in visual images that lead to precancerous lesions in cervical cancers. The algorithm-based visualization of images has been reported to provide better insight into precancerous lesions, with a reported accuracy of 0.9, than routine screening tests.
Lung Cancer Diagnosis with Deep Learning Technique
NCI funded researchers of New York University used Deep Learning (DL) algorithms to identify gene mutations from pathophysiological images of lung tumors using Predictive Analytics. The pathophysiological images of lung tumours were collected from the Cancer Genome Atlas and used to build an algorithm that can predict specific gene mutations by visual inspections of the pathophysiological images. This method can very accurately predict the different types of lung cancers and the corresponding gene mutations from the analyses of the images.
Thyroid Cancer with Deep Convoluted Neural Network
Deep Convoluted Neural Network (DCNN) models were used to develop an accurate diagnostic tool for thyroid cancers by analysing images from ultrasonography. 1,31,731 ultrasound images from 17,627 patients with thyroid cancer and 1,80,668 images from 25,325 controls were collected from the thyroid imaging database of Tianjin Cancer Hospital. Those ultrasound images were modelled into a DCNN algorithm. The DCNN model showed similar sensitivity and improved specificity in identifying patients with thyroid cancer compared with a group of skilled radiologists.
AI/ML for Personalized Medicines
Researchers at Aalto University, University of Helsinki and the University of Turku developed a machine learning algorithm that can accurately predict how combinations of different antineoplastic drugs can kill various types of cancerous cells. This algorithm was obtained from data collected from a study that investigated the association between different drugs and their effectiveness in treating cancers. The model developed was found to show associations between different combination of drugs and cancer cells with high accuracy; the correlation coefficient of the model fitted was reported to be 0.9. This AI model can help cancer researchers to prioritize which combination of drugs to choose from a plethora of options for further research investigation. This depicts how AI and ML can be used for the development of personalized medicines.
Future challenges of AI/ML in cancer diagnosis
Data Science is shaping the future of the health care industry like never before. There has been a spurt of growing interests in AI and ML for the diagnosis of precancerous lesions and surveillance of cancerous lesions. The researchers are exploring to develop AI algorithms that help in the diagnosis of many other cancers. However, each type of cancer behaves differently and the consequent changes would be a significant challenge for the algorithms. Machine learning tools can overcome these challenges by training algorithm of these subtle changes. This would drastically improve decision making for clinicians.
One of the biggest challenges of the Artificial Intelligence today is the acceptance of the technology in the real world, particularly related to medical diagnoses of terminally ill patients where decision making plays a critical role in the longevity of the patient. The AI black box problem augments this problem further. AI black box refers to the fact that programmers can see input and output data only but how does an algorithm work is not known.
Regulatory aspects of AI/ML in cancer diagnosis
In 2019, US FDA publishing a discussion paper entitled “Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) – Discussion Paper and Request for Feedback.” The intention of FDA was to develop a regulatory framework for the medical software by issuing draft guidance on the Predetermined Change Control Plan outlined in the discussion paper. The Predetermined Change Control Plan mapped out a regulatory premarket review for AI/ML-based SaMD modifications.
In 2021, FDA published a draft guidance document entitled “Artificial Intelligence and Machine Learning (AI/ML) Software as a Medical Device Action Plan.” The FDA encouraged the development of the harmonized Good Machine Learning Practices of AI/ML-based SaMD through the participation of industrial and other stakeholders in consensus standards development efforts. This guidance was built upon the October 2020 Patient Engagement Advisory Committee (PEAC) meeting focused on patient trust in AI/ML technologies.
The FDA supports regulatory science efforts on the development of methodology for the evaluation and improvement of machine learning algorithms, including for the identification and elimination of bias, and on the robustness and resilience of these algorithms to withstand changing clinical inputs and conditions.
Conclusion
The employment of Predictive Analytics in cancer diagnosis has answered major challenges experienced in cancer diagnosis and treatment. It can help early screening of precancerous lesions and avert the mortality rate in cancer patients. AI/ ML provides accurate detection and prognosis of cancers, thereby reducing the incidents of false positives, false negatives and overdiagnosis. These techniques can also be used to track the prognosis of the cancers in the case of immunotherapies and radiotherapies. The AI/ ML has also potential applications in the development of personalized medicines by developing specific therapies for each specific cancers.
By detecting cancers early and accurately, prognosis of cancer treatment would be greatly improved. The early detections of cancers will have a huge impact on the cost-saving of the complicated cancer treatments. This could also have a huge impact on the cancer survival rates as the mortality rates could be drastically decreased on early detection of the cancers.
If you are struggling to make use of cancer data and need help to develop Machine Learning Models, then feel free to reach out to us. At Let’s Excel Analytics Solutions, we help our clients by developing cloud-based software solutions for predictive analytics using Machine Learning.
Predictive data science is no longer limited only to data scientists and engineers. Interested to explore what you can do in the food & beverage industry? Read this article to know how your competitors are leveraging predictive data science to improve their operations. Progress happens with each step taken. With the market becoming more competitive than ever, everyone is eager to find a breakthrough solution. According to a news report on CISION PR Newswire, the global food and beverages market reached a value of nearly $5,943.6 billion in 2019, having increased at a compound annual growth rate (CAGR) of 5.7% since 2015. The market is expected to grow at a CAGR of 6.1% from 2019 and reach $7,525.7 billion in 2023. Meaning that there are massive amounts of data just waiting to be analysed and processed for meaningful insights using predictive data science. Let us now see what data science and analytics can do for the food and beverage industry.
Predictive Data Science in Restaurant Industry:
When talking about the benefits of predictive data science in food, we cannot leave out restaurants. Restaurant owners do not seem to realize the tremendous amounts of data that is generated from their customers. Therefore, there are chances that they miss opportunities to decrease costs and improve customer experience. With the explicit and precise implementation of data science, restaurant owners can obtain real-time analysis of their customers’ data and make the required improvements. For instance, owners and founders can point out their highest selling or most expensive items, the quality of food offered, and more. Based on this data, they can make informed choices, and also fix their mistakes.
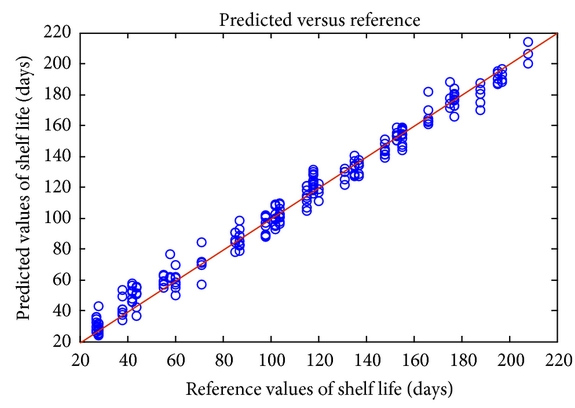
Predicting shelf life:
Each type of food has its own shelf-life, causing it to expire over time. However, there are certain items of consumption that only grow better with time. For instance, wine gets better with time, but fresh produce will expire. Different items of food and drink have different shelf lives and managing all of them independently is a major challenge for this industry. The procedure for dealing with wine is very different compared to the procedure for dealing with expired products. But, by incorporating predictive data science into the picture, data engineers can predict the shelf life of produce, thus ensuring pre-emptive action is taken to reduce the amount of waste and saving money and time.
Sentiment Analysis:
Social media, review websites and food delivery apps have allowed the food industry to do something that was not possible in the past, i.e., sentiment analysis. Using NLP, organizations can analyse their social media channels and discover patterns and trends in the data. This will allow them to discover the most popular foods and beverages of any season. It also allows them to discover the popular foods during special occasions and other festivities. Brands, restaurants, and organizations can, in turn, be more receptive to people’s demand and act accordingly. Google analytics can be a helpful medium in this case.
Better Supply Chain Transparency:
Let us now look at another example of how data analytics can benefit growers, transporters, processors, and food retailers:
Information about the weather is also entered into the database. Inputs about precipitation and temperatures can be automated.
The farmers enter the test results of the soil, along with the planting and harvesting data into a database used by a particular software program.
The logistics company that transports the farmer’s crop from the farm to the processing mill, inputs the start and end times for the trip in the database.
The food processor enters the start and stop times for various stages of the processing, sorting, washing, packaging, and placing in cold storage can all be tracked with automated sensors.
The product is then monitored from the processor to the retailer. Any delays that could cause the food to spoil can be easily identified.
At the destination, the vendor can record the quality of the food when it arrives,
Customer feedback on social media can also be added to the collected data, to provide further insight to the food supply chain.
The entire supply chain can access this information. If there arises any problems, changes can be made to this process to prevent a further recurrence. Moreover, retailers can choose to accept or reject the shipment based on this data. The software performs an analysis of the data and provides intelligent and accurate conclusions to all parties involved in the supply chain. Analytics software takes the help of a large number of sources for making its analysis, including social media. Both structured and unstructured data is used for the analysis. This collection of data is known as big data.
Measuring Critical Quality Attributes:
There are certain primary attributes against which the food and beverage industry measures the quality of its products. These attributes can be a great asset in marketing them – for example, the alcohol concentration in beer. However, conventional methods of measuring primary attributes are time-consuming. In case of beer, the alcohol level is measured using a method known as near-infrared spectroscopy. This method, however, is time-consuming and delays the production process. Predictive Data science and analytics allows organizations to explore other methods that are faster and more cost-effective, like the Orthogonal Partial Least Square Regression and multiple regression models to measure alcohol content and colour.
Better Health Management:
Consumers wish the food industry to be more transparent. The leading firms of the multi-billion-dollar beef industry realised this when they gathered for Beef Australia 2018, a convention that sees over 90,000 visitors. Consumers expect restaurants and organisations to be more forthright with them. They expect to be completely aware of how the food was produced, how the livestock was treated and what chemicals, if any, were used in the food. They want to be completely aware of what they are consuming. Data science and analytics helps incorporate transparency within these supply chains, so that organizations can be more honest with their customers. Transparency also assists in solving problems related to logistics and supply. For instance, it becomes easier to track contaminated food supplies to their storage locations, thus eliminating the chances of spread of food-borne diseases. Predictive data science and analytics allows organizations to protect food health and prevent cross-contamination. Geographical data, along with satellite data and remote sensing techniques, allows data analysts to ascertain changes. This information, along with data on temperature, soil property, and vicinity to urban areas, can predict which part of the farm is likely to be infected with pathogens, and take immediate action beforehand. Another excellent example is when cities are short on food inspectors – data analytics can analyse historical data on 13 key variables to help pinpoint the riskiest establishments, making better use of limited food inspectors.
Predictive Data Science for Food Innovations
Organizations need to keep pace with the changing demands of the consumers. With the fluctuation in their tastes according to season, time of day, weather, mood, etc, it becomes crucial for the organizations to take the assistance of predictive data science. This data is then converted into meaningful information which aids in making important decisions, as well as to improve sales and overall performances.
Food Marketing
Predictive data science also assists businesses in improving their marketing campaigns, developing creative and high demand products, and empowering firms to stay updated over their competition’s growth rate, control quality as well as assess decisions regarding purchasing and prices. The data also helps businesses keep track of certain crucial factors, like the quality of their products, by gauging if the composition of the product has been altered in any way.
Conclusion
Predictive data science and analytics has definitely brought about a positive growth in certain industries, including the food and beverage industry. This industry is prone to its fair share of difficulties. With the ever-growing population, consumers are always looking to choose the best option that they can get. Since the consumer is the key, organizations need to make decisions revolving around the consumers’ tastes. Data science enables businesses to derive conclusions about which option will be best suited for the consumers. It allows organizations to collect and analyse data and derive at interesting patterns and trends over a period of time. The technology can also be used to conceive several creative solutions to problems plaguing the industry while bringing positive developments to food and beverage.
Data is everywhere. From small businesses to large multinational organizations, data is used in almost every area of study and work. From the small mathematical problems solved by a child to the complex functions executed in large organizations, data is used almost everywhere.
Data is one of the most important components of any organization, because it assists leaders in making decisions based on absolute certainty, comprising of facts, statistical results and trends. Any result based on correct and concise data tends to be correct. Data can reveal a lot about an organization, and organizations rely heavily on this data.
Due to the growing relevance and importance of data, data science came into the picture. Data science is a multidisciplinary field. It uses algorithms, scientific procedures and approaches to derive conclusions from massive amounts of data. This data can be either structured or unstructured. In this article, we shall be looking at data science in the healthcare industry.
Data Analytics in Healthcare
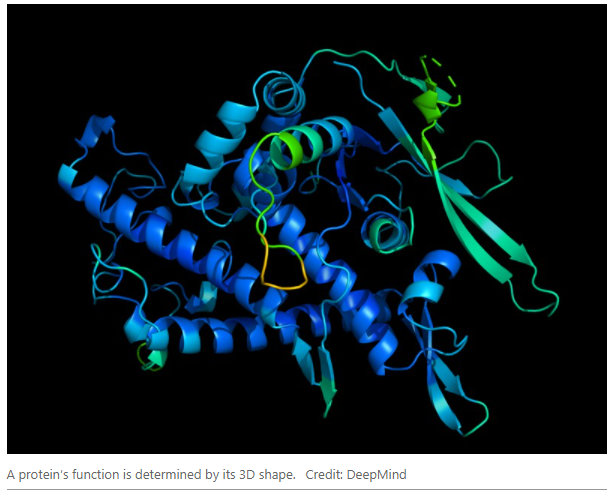
Medicine and healthcare are two of the most important components of our lives. Traditionally, medicine and medical advice was given solely by the doctors based on the patient’s symptoms. However, this was not always accurate and was prone to errors. With the advancements in the field of data science, it is now possible to obtain a more accurate diagnosis. The AI is being used not only as a tool for diagnosis but also for break through discoveries. In a latest advancement Google has achieved a huge success in unfolding protein structures. The very core of the problem that many biochemical Scientists were trying to solve from many decades!
Scientists have also developed ‘DNA Nanopore Sequencer’ which is a tool that helps patients before they suffer from septic shock. It provides genetic sequences mapping, which abbreviates the time span of the information preparing activity. Moreover, this tool recovers genomic information, BAM document controls, and provides calculations. The new health data science perspective allows applying data analytics, that are collected from various fields, to augment the healthcare sector. There are several areas in healthcare, such as drug discovery, medical imaging, genetics, predictive diagnosis and others which make full use of the results derived at through data science techniques. With ERM’s, clinical trials and internet research, there is so much data being accumulated every day. With the majority of people seeking healthcare advice online, gathering data has become increasingly convenient.
How can it work?
Let us now try to derive an insight into how data science and healthcare can become mutually beneficial.
Data management and Data Governance: The opportunities derived from managing data efficiently are extensive. When data is managed effectively, it makes information easily accessible to all those in the healthcare industry. When data is analysed and shared effectively among doctors and healthcare providers, it will enable them to be more personal and humane in their approach towards treatment. Since the healthcare sector has its fair share of risks, data analytics should always be at the top of its game; it should be up-to-date and acute. The Data related to Medical records, ongoing condition charts of patients, medical database, genetic research, medical image diagnoses can be effectively leveraged to unfold valuable information.
Each patient’s medical records can be combined into one dataset, and then analysed and utilised when needed, to derive at the required conclusions.
Data management also involves data sharing. Data can be shared across several datasets, eliminating the need for excessive office work.
When data is analysed repeatedly, it will bring out any and all errors in clinical data.
Cloud-based clinical software enables faster processing of data, leading to time saved when deciding on treatment or obtaining test results.
Machine learning assists in shortening the process of drug discovery.
Challenges ahead
While data governance has been recognized as crucial to healthcare, there are opportunities to expedite the prioritization of data governance, so that data is accurate, complete, structured, precise and available. Data governance plays a pivotal role in patient engagement, care coordination, and looking after the overall health of the community. If data is not governed properly, different healthcare companies will release inconsistent data which will prove to be a major hindrance. Healthcare data science apps exist in order to avoid such inconveniences.
Workflow Optimization and Process Improvements: Big data analytics is not as profound in healthcare. Hence, certain decisions are taken based on the ‘gut instinct’. Apart from this, lack of coherent healthcare information exchange between the systems and shortage of skilled workers to fill knowledge gaps are other two challenges involved in the process.
Opportunities Genetics/Genomics
Treatment personalization: With the introduction of new technologies, including new forms of genomic profiling or sequencing, it provides a new look at the world of genomics. The massive amounts of data today produce genetic data faster than ever. This is partly because the techniques of structuring data, lag behind the ability to actually get the data. Healthcare data science produces copious amounts of data, but that data needs to be made sense of. Some of the challenges in the field of genomics are:
Studying human genetic variation and its impact on patients
Identifying genetic risk factors for drug response
Opportunities in Medical Imaging
Medical Imaging: Medical imaging refers to the process of creating a visual representation of the body for medical analysis and treatment. If is a non-invasive method for doctors to look inside the human body and decide on the required treatment plan. With the swift growth of healthcare and artificial intelligence, this process of medical imaging becomes easier. Some of the types of medical imaging include tomography, longitudinal tomography etc. The primary methods of medical imaging are X-ray computer tomography (CT), PET, and MRI. Medical imaging needs the images to be absolutely accurate. Even minor discrepancies might lead to disastrous results, which can be catastrophic to the patients. The images need to be precisely viewed and interpreted. Data analysis refines these images by enhancing their characteristics like
Opportunities in Predictive Analytics
Predictive analytics refers to a technology that learns from experience, i.e. data, to predict a patient’s behaviour. It builds a connection between the data and the consequent actions which need to be taken based on that data. Predictive analytics allows healthcare to use predictive models or models found specifically in health data science. This allows identification of risks even before they occur. However, there are some drawbacks to predictive analytics.
Predictive analytics is already being used in healthcare manufacturing to meet safety and efficacy requirements of drug products and medical devices.
Opportunities in Drug Research
If we look back to the time of another major pandemic, the Spanish Flu, we see that drugs and vaccines took a considerable amount of time. But now, with the help of data science, data from millions of test cases can be processed within weeks. Development of vaccines and other drugs has become easier and less time-consuming.
How can Let’s Excel Analytics Solutions help here
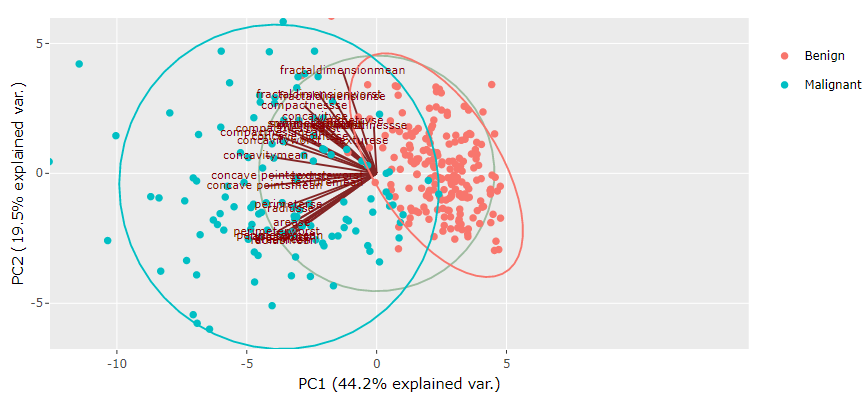
We at Let’s Excel develop easy-to-use software interfaces using Artificial Intelligence and Machine Learning algorithms to take healthcare research to next level with data science. Below is an example of the diagnosis of a tumor as benign or malignant using DataPandit‘s MagicPCA solution.
Advantages
Lesser time taken and more precise outcomes lead to more effective work processes.
Healthcare providers and other staff get the chance to perform more tasks in limited time.
More effective work processes lead to higher recovery rates, faster reactions to crises and, in turn, less fatal results.
Patients get more personalized treatments.
Conclusion
Healthcare has a vast amount of data being generated every day. This data needs to be made sense of, it needs to be structured and organized so that meaningful conclusions can be derived at from the data. The healthcare industry needs to heavily utilize this data so that patients’ lifestyle can improve, diseases can be predicted before their inception. Moreover, with medical imaging analysis, it is now possible for doctors to find even the most microscopic tumours. Doctors can also monitor the conditions of their patients from remote locations.
Data science is already doing wonders for the healthcare industry. It is only a matter of time before it proves itself to be invaluable.