Introduction
Ever wondered why Clive Humby famously coined the 'Data is new oil' phrase? Well, this blog article tells you exactly what he meant. The latest advancements in data analytics, cloud infrastructure, and increased emphasis on making data-driven decisions have opened up several avenues for developing Data Science Products. People can build amazing data-based products that can generate revenues. In other words, the data is the new money-making machine. In this article, we will discuss the top 3 things that you must know about data science products.
# 1: What is a Data Science Product?
Data Science Product is a new era money-making machine that is fueled by data and built using machine learning techniques. It takes data as input and gives out valuable business insights as an output.
#2: Examples of Data-based Products
Classic examples of data products include Google search and Amazon product recommendations, both these products improve as more users engage. But the opportunity for building data-based products extends far beyond the tech giants. These days companies of all range of sizes and across almost all sectors are investing in their own data-powered products. Some inspirational examples of data science products that are developed by non-tech giants are as below:
HealthWorks
It mimics consumer choice in Medicare Advantage. The product compares and contrasts more than 5000+ variables across plan costs, plan benefits, market factors, regulatory changes, and many more. It helps Health Plans identify the top attributes that lead to plan competitiveness, predict enrolments, design better products and create winning plans.
Cognitive Claims Assistant
Damage assessment in vehicles is an important step for insurance claims and auto finance industry. Currently, these processes involve manual interventions requiring a long turnaround time. Cognitive Claims Assistant (CCA) by Genpact automates this process. The data product not only reduces cost and time in the process but also accurately estimates the cost of repairs.
#3: How to Build Data Powered Products?
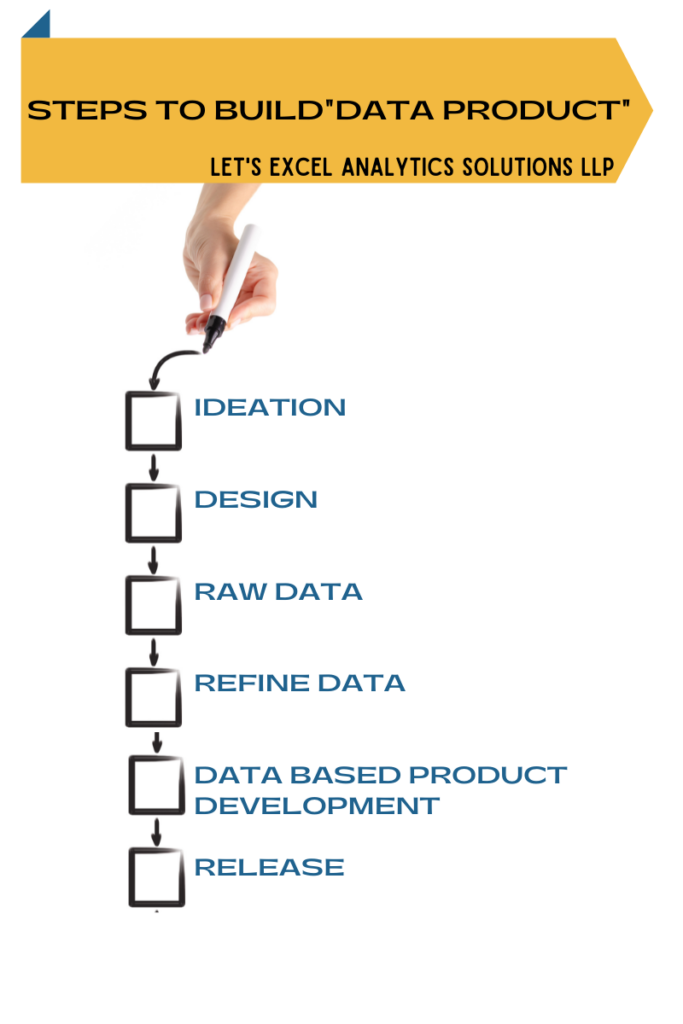
Do you want to build a data science product too? Here are the five steps that will help you to build a good data science product:
Step 1: Ideation and Design of Data Product
Ideation
The first step of building a data science product is Conceptualizing the product. Conceptualization starts with identifying potential opportunities. A good data science product is the one that solves a critical business need. An unsolved business need that can be solved using data is an opportunity for building data products.
Design
Design the data structure that you will need to solve the business need. This often involves brainstorming on various data inputs and their corresponding valuable outputs that will solve the business need.
Step 2: Get the Raw Data
The second step in building data products is getting the data. If you already own the data, you are already covered for this. All you have to do is move on to the next step. If you don’t have the data then you need to generate or gather it.
Step 3: Refine the Data
As they rightly say, data is the new oil but it is of no use until it is refined like an oil. Understand the structure of your data. Refine, clean, and pre-process it if it is unstructured. Always remember the golden rule-‘Garbage in is Garbage out!’ Knowing the data helps you clearly define the inputs and outputs from your data science product.
Step 4: Data Based Product Development
This is the most tricky part in data science product development and needs a strong knowledge of the business process, business needs, statistics, mathematics, and coding. This knowledge forms the backbone of the data product. In the majority of the cases, this step involves building a machine learning model using domain knowledge. In some cases, it could also involve simple graphical outputs for exploratory analysis of the data. No matter what is the output the codes developed for executing the desired process need to be tested and validated for real-life use of the data product.
Step 5: Release!
This is the last step in data product development. In this step, tried, tested, and validated data science product is deployed on a cloud. The data product buyers can simply log in from anywhere in the world and use the product.
Conclusion
Anybody who owns the treasure trove of the data should develop a ‘Data Science Product’ or a ‘Data Product’. Now the question arises, is it possible to build data products without coding knowledge? And the answer is, absolutely yes! You can use our data analytics platforms that are specially built for non-coders. All you have to do is arrange your data meaningfully and just make few clicks to build your base model described in Step 4 of How to build data products as described above. When you deploy the model on the cloud your money-making machine becomes a reality. If you don’t like the idea of doing it all yourself, then you always have an option to outsource.
Like any other product, the success of the data product is dependent on its usability. Half the battle is won with a strong business case. The remaining battle can be won with mathematics, statistics, and computer science. This is exactly where we can contribute. Our aim to accelerate the data product development process. Let's unite your domain knowledge and data with our data modeling capabilities. Let's build amazing data science products!