Predictive Analytics in Cancer Diagnosis
Introduction
GLOBOCON 2020, one of the key cancer surveillance projects of the International Agency for Research on Cancer (IARC), published recent statistics of global cancer epidemiology. According to this report, 19,292,789 new cancer cases were reported in 2020 i.e., a two-fold increase in the number of cases as reported in 2018. For over 19 million cases of cancer reported, 9,958,133 cancer-related deaths were reported in the same year. As per the estimates of the International Agency for Research on Cancer (IARC), every 1 person in 5 persons is likely to develop cancer during their lifetime. In this article we are going to discuss how Predictive Analytics can play a major role in changing Cancer Statistics.
Cancer Statistics: 2020
|
| Males | Females |
|
Population |
3,929,973,836 | 3,864,824,712 |
|
Number of new cancer cases |
10,065,305 | 9,227,484 |
|
Number of cancer deaths | 5,528,810 | 4,429,323 |
| 5 year prevalent cases | 24,828,480 | 4,429,323 |
| Top 5 most cancers excluding non-melanoma skin cancer | Lung, Prostrate, Colorectum, Stomach, Liver | Breast, Lung, Colorectum, Prostrate, Stomach |
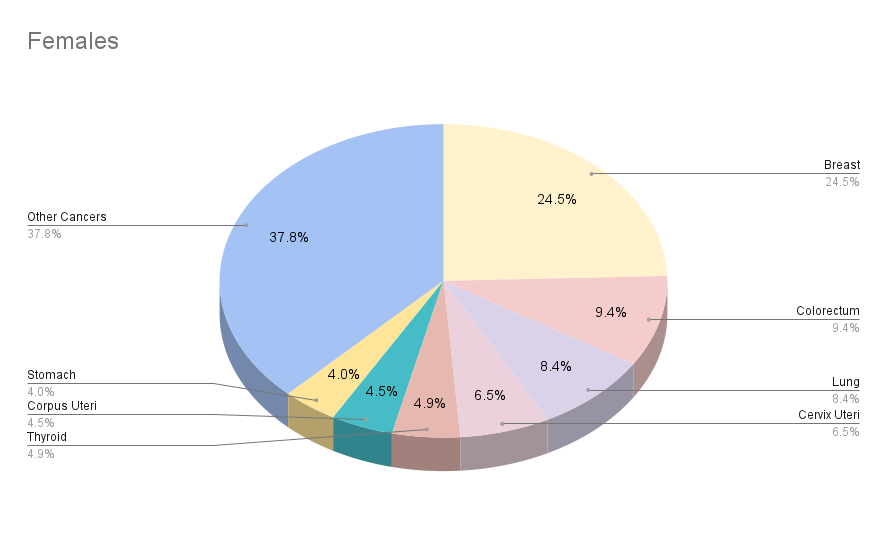
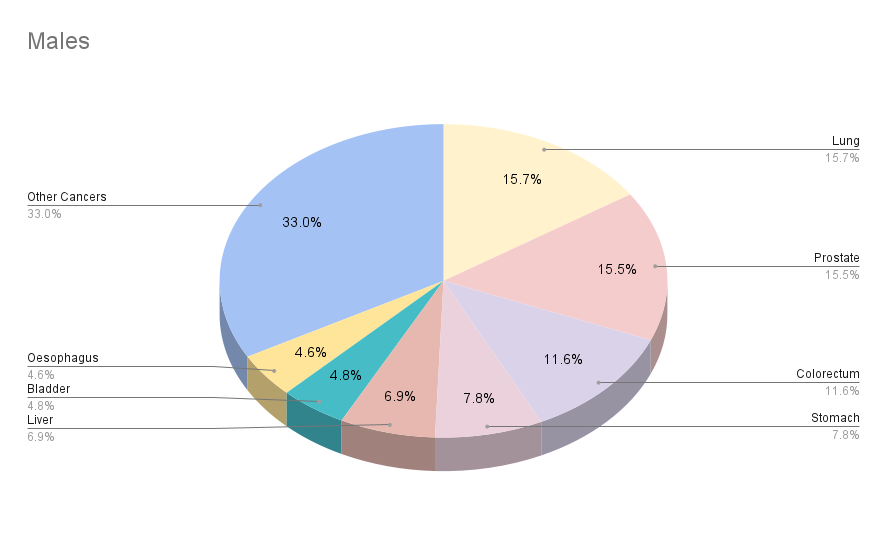
Estimated Number of Cases Worldwide
These alarming and constantly rising figures have refocused the attention of medical scientists on the early screening and diagnosis of cancers using Predictive Analytics. Because cancer mortality and morbidity can be reduced by early detection and treatment of cancer.
American Cancer Society (ACS) issues updated guidelines and guidances related to an early screening of cancers to assist in making well informed decisions about the tests for early detection of some of the most prevalent cancers (breast cancer, colon and rectal cancer, cervical cancer, endometrial cancer, lung cancer, and prostate cancer). The early detection of precancerous lesions and cancers is broadly divided into three categories:
Early cancer diagnosis
Cancers respond very well to the treatment only if diagnosed early that, in turn, increases the chances of cancer survival. As per WHO guidance, early diagnosis is a three-step process that must be integrated and provided in a timely manner.
- Awareness of cancers and accessing care as early as possible
- Clinical evaluation of cancers, appropriate diagnosis and staging of cancers
- Access to the right treatment at the right stage.
Screening of cancers
Screening identifies specific markers of cancers that are suggestive of particular cancer. For example, visual inspection with Acetic Acid (VIA) test can be used for early screening of cervical cancers in women. Cervical lesions turn white for a few minutes after application of acetic acid.
However, the early diagnosis and screenings of cancer suffer from drawbacks like false positives, false negatives, and overdiagnosis which may lead to more invasive tests and procedures. To overcome this problem, scientists are using the power of Predictive Analytics based on Artificial Intelligence and Machine Learning.
Introduction to Artificial Intelligence (AI)
Artificial Intelligence (AI) is a great tool for Predictive Analytics and it is defined, in Webster’s dictionary, as a branch of computer science dealing with the simulation of intelligent behaviour in computers. In other words, it is the capability of machine to imitate intelligent human behaviour.
One of the early pioneers of Artificial Intelligence, Alan Turings, published an article in 1950 entitled “Computing Machinery and Intelligence.” It introduced the so-called, Turing test, to determine if a computer can exhibit the same level of intelligence as demonstrated by humans. The term “Artificial Intelligence” was coined by John McCarthy at the Artificial Intelligence (AI) conference at Dartmouth College in 1956. It was Allen Newell, J.C. Shaw, and Herbert Simon who introduced the first AI-based software program namely, The logic Theorist.
Majority of Artificial Intelligence (AI) applications use Machine Learning (ML) algorithms to find patterns in the datasets. These patterns are used to predict the future outcomes.
The basic framework of Artificial Intelligence (AI) consists of three main steps:
- Collecting input data
- Deciphering the relationship between input data
- Identifying unique features of sample data
Introduction to Machine Learning (ML)
Machine learning (ML) is also another tool for Predictive Analytics and is defined in Webster’s dictionary as the process by which a computer is able to improve its own performance by continuously incorporating new data into an existing statistical model. It allows the system to reprogram itself as more data is added and eventually increasing the accuracy of the task assigned.
In the case of Machine learning (ML), it’s an iterative process so that the predictability of the system is improved each time. Most Machine Learning (ML) algorithms are mathematical equations in which sample data is plotted to observed variables, termed as features, and the outcomes termed as labels. The labels and features are used for the classification of different ML tools and techniques. Based on the label type, Machine Learning (ML) algorithms can be categorised into:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
In supervised learning, models are trained based on labelled datasets. For the purpose of prediction, the model needs to map the input variables with the output variables using a know mathematical function. Supervised learning can be used for understanding, Classification and Regression problems.
In unsupervised learning, data patterns are found in the un-labelled data and the endpoint of the unsupervised learning is to find characteristics patterns in the data. Unsupervised learning is used for identifying Clustering and Association in datasets.
Reinforcement learning is the ‘learning’ by interacting with the environment. A reinforcement learning algorithm makes decisions based on its past experiences and also by making new explorations.
The PCA part of MagicPCA 1.0.0. is an unsupervised Machine Learning Approach, whereas the SIMCA part of it is a Supervised Classification Technique.
Rising Interest in Biomedical Research
In the initial years, the journey of AI was not so easy, as can be seen in the period of 1974-1980, which is known as AI winter. During this period the field experienced its low in terms of researcher’s interests and government funding. Today, after decades of advances in data management and superfast computers, and renewed interests of government and corporate bodies, it is a practical reality and finds its applications in a wide variety of fields like e-commerce, medical sciences, cybersecurity, agriculture, space science, automobile industry, etc.
As the phrase “Data Science is everywhere” picked up, biomedical researchers started delving into Artificial Intelligence (AI) and Machine Learning (ML) to look for a better solution through Predictive Analytics. One inspiring story of Regina Barzilay, a renowned professor of Artificial Intelligence (AI) and a breast cancer survivor, portrays how her diagnosis of breast cancer reshaped her research interests. She hypothesized that AI and ML tools can extract more clinical information that helps clinicians make knowledgeable decisions. She collected data from medical reports and developed Machine Learning algorithms to interpret the radio diagnostic images for clinicians. One of the models developed by her has also been implemented in clinical practice that helps radiologists to read diagnostic images very well.
Current scenario: Predictive Analytics in Cancer Diagnosis
The concept of AI/ML has long been employed as Predictive Analytics tool in the radiodiagnosis of precancerous lesions and tumours.
The AI system reads the images generated by various radiological techniques like MRI, PET scan, etc., and processes the information contained in them to assist clinicians make conscious decisions on the diagnosis and progression of the cancers.
Breast Cancer Diagnosis with QuantX
The FDA’s Center for Devices and Radiological Health (CDRH) has approved the first AI-based breast cancer diagnosis system for Predictive Analytics. QuantX was developed by Qlarity Imaging (Paragon Biosciences LLC). QuantX is described as a computer-aided (CAD) diagnosis software system that assists radiologists in the assessment and characterization of breast anomalies using Magnetic Resonance Imaging (MRI) data. The software automatically registers images and segmentations (T1, T2, FLAIR, etc.), and analyses user-directed regions of interest (ROI). QuantX extracts this data from the ROI to provide computer-aided analytics based on morphological and contrast enhancement characteristics. These imaging analytics are then used by an artificial intelligence algorithm to get a single value, known as QI score, which is analysed relative to the reference database. The QI score is based on the machine learning algorithm that is generated from a training subset of features calculated on segmented lesions.
Cervical Cancer Diagnosis with CAD
National Cancer Institute (NCI) has also developed a computer aided program (CAD) that analyses digital images taken of women’s cervix and identify potentially precancerous changes that require immediate medical attention. This Artificial Intelligence-based approach is called Automated Visual Evaluation (AVE). A large set of data, around 60000 cervical images, was generated using the precancerous and cancerous lesions to develop a machine learning algorithm. This algorithm recognizes patterns in visual images that lead to precancerous lesions in cervical cancers. The algorithm-based visualization of images has been reported to provide better insight into precancerous lesions, with a reported accuracy of 0.9, than routine screening tests.
Lung Cancer Diagnosis with Deep Learning Technique
NCI funded researchers of New York University used Deep Learning (DL) algorithms to identify gene mutations from pathophysiological images of lung tumors using Predictive Analytics. The pathophysiological images of lung tumours were collected from the Cancer Genome Atlas and used to build an algorithm that can predict specific gene mutations by visual inspections of the pathophysiological images. This method can very accurately predict the different types of lung cancers and the corresponding gene mutations from the analyses of the images.
Thyroid Cancer with Deep Convoluted Neural Network
Deep Convoluted Neural Network (DCNN) models were used to develop an accurate diagnostic tool for thyroid cancers by analysing images from ultrasonography. 1,31,731 ultrasound images from 17,627 patients with thyroid cancer and 1,80,668 images from 25,325 controls were collected from the thyroid imaging database of Tianjin Cancer Hospital. Those ultrasound images were modelled into a DCNN algorithm. The DCNN model showed similar sensitivity and improved specificity in identifying patients with thyroid cancer compared with a group of skilled radiologists.
AI/ML for Personalized Medicines
Researchers at Aalto University, University of Helsinki and the University of Turku developed a machine learning algorithm that can accurately predict how combinations of different antineoplastic drugs can kill various types of cancerous cells. This algorithm was obtained from data collected from a study that investigated the association between different drugs and their effectiveness in treating cancers. The model developed was found to show associations between different combination of drugs and cancer cells with high accuracy; the correlation coefficient of the model fitted was reported to be 0.9. This AI model can help cancer researchers to prioritize which combination of drugs to choose from a plethora of options for further research investigation. This depicts how AI and ML can be used for the development of personalized medicines.
Future challenges of AI/ML in cancer diagnosis
Data Science is shaping the future of the health care industry like never before. There has been a spurt of growing interests in AI and ML for the diagnosis of precancerous lesions and surveillance of cancerous lesions. The researchers are exploring to develop AI algorithms that help in the diagnosis of many other cancers. However, each type of cancer behaves differently and the consequent changes would be a significant challenge for the algorithms. Machine learning tools can overcome these challenges by training algorithm of these subtle changes. This would drastically improve decision making for clinicians.
One of the biggest challenges of the Artificial Intelligence today is the acceptance of the technology in the real world, particularly related to medical diagnoses of terminally ill patients where decision making plays a critical role in the longevity of the patient. The AI black box problem augments this problem further. AI black box refers to the fact that programmers can see input and output data only but how does an algorithm work is not known.
Regulatory aspects of AI/ML in cancer diagnosis
In 2019, US FDA publishing a discussion paper entitled “Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) – Discussion Paper and Request for Feedback.” The intention of FDA was to develop a regulatory framework for the medical software by issuing draft guidance on the Predetermined Change Control Plan outlined in the discussion paper. The Predetermined Change Control Plan mapped out a regulatory premarket review for AI/ML-based SaMD modifications.
In 2021, FDA published a draft guidance document entitled “Artificial Intelligence and Machine Learning (AI/ML) Software as a Medical Device Action Plan.” The FDA encouraged the development of the harmonized Good Machine Learning Practices of AI/ML-based SaMD through the participation of industrial and other stakeholders in consensus standards development efforts. This guidance was built upon the October 2020 Patient Engagement Advisory Committee (PEAC) meeting focused on patient trust in AI/ML technologies.
The FDA supports regulatory science efforts on the development of methodology for the evaluation and improvement of machine learning algorithms, including for the identification and elimination of bias, and on the robustness and resilience of these algorithms to withstand changing clinical inputs and conditions.
Conclusion
The employment of Predictive Analytics in cancer diagnosis has answered major challenges experienced in cancer diagnosis and treatment. It can help early screening of precancerous lesions and avert the mortality rate in cancer patients. AI/ ML provides accurate detection and prognosis of cancers, thereby reducing the incidents of false positives, false negatives and overdiagnosis. These techniques can also be used to track the prognosis of the cancers in the case of immunotherapies and radiotherapies. The AI/ ML has also potential applications in the development of personalized medicines by developing specific therapies for each specific cancers.
By detecting cancers early and accurately, prognosis of cancer treatment would be greatly improved. The early detections of cancers will have a huge impact on the cost-saving of the complicated cancer treatments. This could also have a huge impact on the cancer survival rates as the mortality rates could be drastically decreased on early detection of the cancers.
If you are struggling to make use of cancer data and need help to develop Machine Learning Models, then feel free to reach out to us. At Let’s Excel Analytics Solutions, we help our clients by developing cloud-based software solutions for predictive analytics using Machine Learning.